Deep Neural Networks
Outline:
- References
- TensorFlow ReLUs
- Deep Neural Network in TensorFlow
- Training a Deep Neural Network
- Save and Restore TensorFlow Models
- Finetuning
- Regularization
- Dropout
References
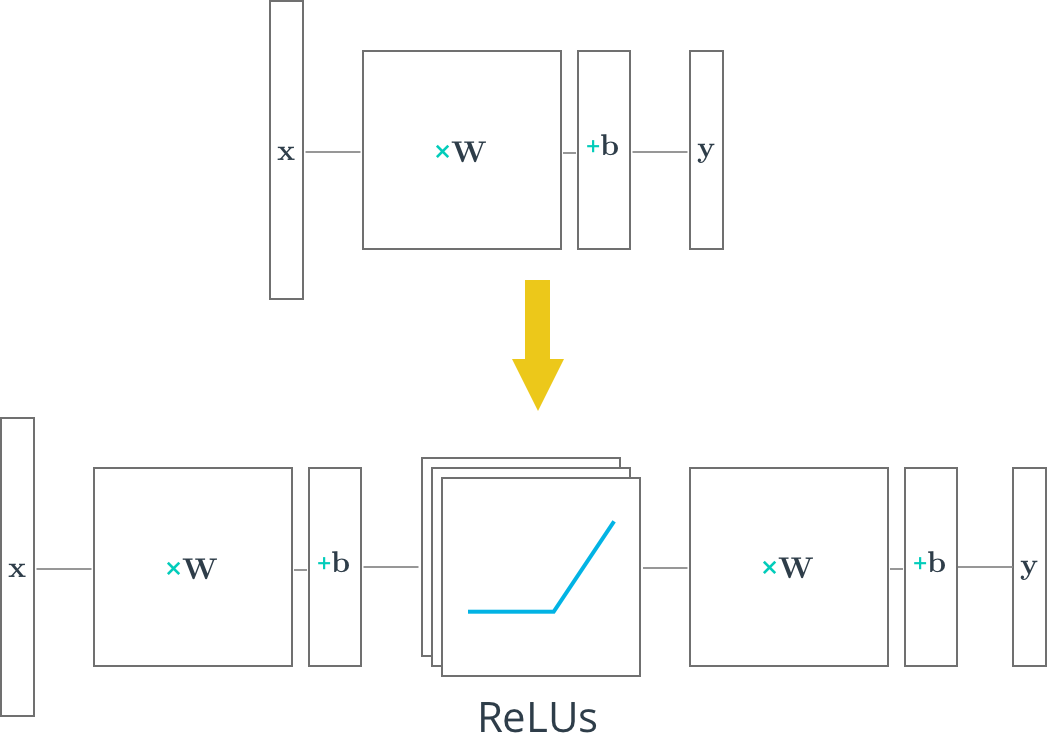
TensorFlow ReLUs
Code:
# Quiz Solution
# Note: You can't run code in this tab
import tensorflow as tf
output = None
hidden_layer_weights = [
[0.1, 0.2, 0.4],
[0.4, 0.6, 0.6],
[0.5, 0.9, 0.1],
[0.8, 0.2, 0.8]]
out_weights = [
[0.1, 0.6],
[0.2, 0.1],
[0.7, 0.9]]
# Weights and biases
weights = [
tf.Variable(hidden_layer_weights),
tf.Variable(out_weights)]
biases = [
tf.Variable(tf.zeros(3)),
tf.Variable(tf.zeros(2))]
# Input
features = tf.Variable([[1.0, 2.0, 3.0, 4.0], [-1.0, -2.0, -3.0, -4.0], [11.0, 12.0, 13.0, 14.0]])
# TODO: Create Model
hidden_layer = tf.add(tf.matmul(features, weights[0]), biases[0])
hidden_layer = tf.nn.relu(hidden_layer)
logits = tf.add(tf.matmul(hidden_layer, weights[1]), biases[1])
# TODO: Print session results
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(logits))
Deep Neural Network in TensorFlow
TensorFlow MNIST
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(".", one_hot=True, reshape=False)
Learning Parameters
import tensorflow as tf
# Parameters
learning_rate = 0.001
training_epochs = 20
batch_size = 128 # Decrease batch size if you don't have enough memory
display_step = 1
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
Hidden Layer Parameters
n_hidden_layer = 256 # layer number of features
The variable n_hidden_layer determines the size of the hidden layer in the neural network. This is also known as the width of a layer.
Weights and Biases
# Store layers weight & bias
weights = {
'hidden_layer': tf.Variable(tf.random_normal([n_input, n_hidden_layer])),
'out': tf.Variable(tf.random_normal([n_hidden_layer, n_classes]))
}
biases = {
'hidden_layer': tf.Variable(tf.random_normal([n_hidden_layer])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
Input
# tf Graph input
x = tf.placeholder("float", [None, 28, 28, 1])
y = tf.placeholder("float", [None, n_classes])
x_flat = tf.reshape(x, [-1, n_input])
The MNIST data is made up of 28px by 28px images with a single channel. The tf.reshape() function above reshapes the 28px by 28px matrices in x into row vectors of 784px.
Multilayer Perceptron
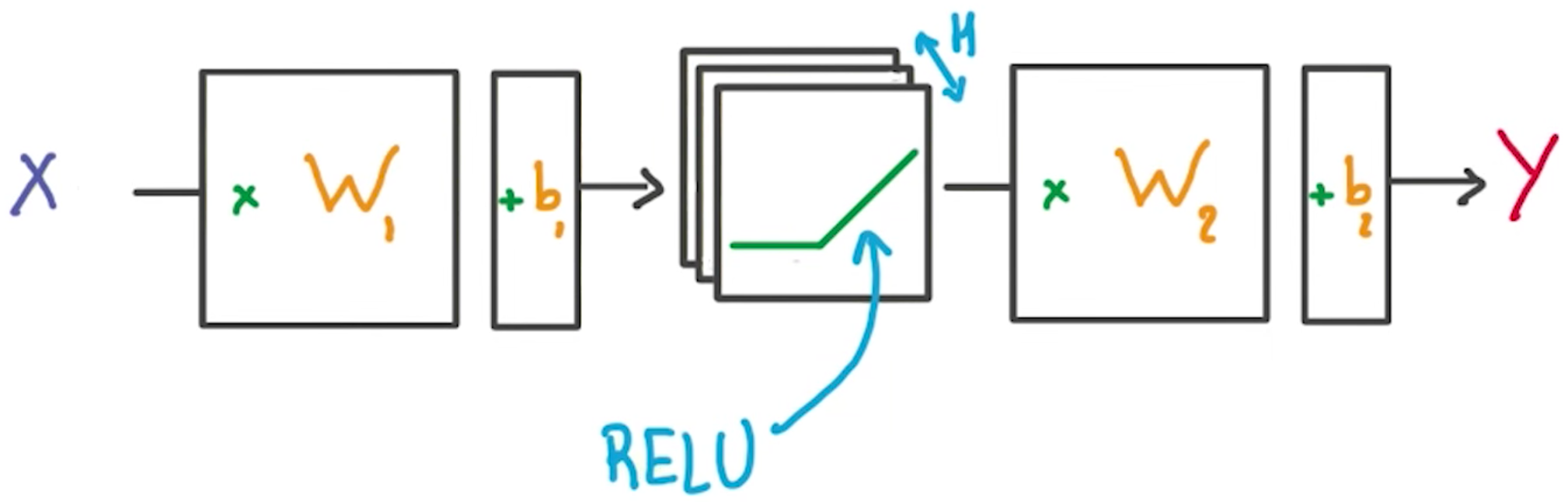
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x_flat, weights['hidden_layer']),\
biases['hidden_layer'])
layer_1 = tf.nn.relu(layer_1)
# Output layer with linear activation
logits = tf.add(tf.matmul(layer_1, weights['out']), biases['out'])
Optimizer
# Define loss and optimizer
cost = tf.reduce_mean(\
tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)\
.minimize(cost)
Session
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
The MNIST library in TensorFlow provides the ability to receive the dataset in batches. Calling the mnist.train.next_batch() function returns a subset of the training data.
Deeper Neural Network
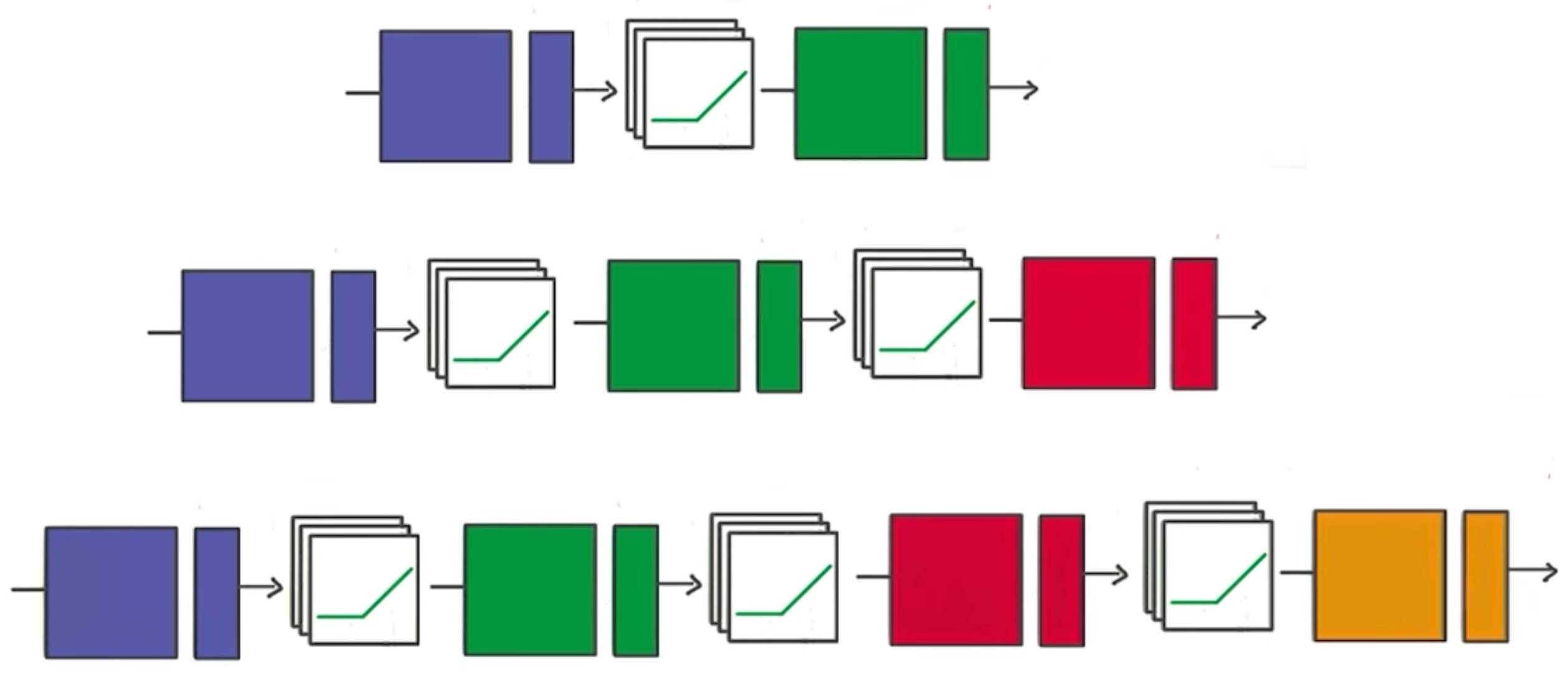
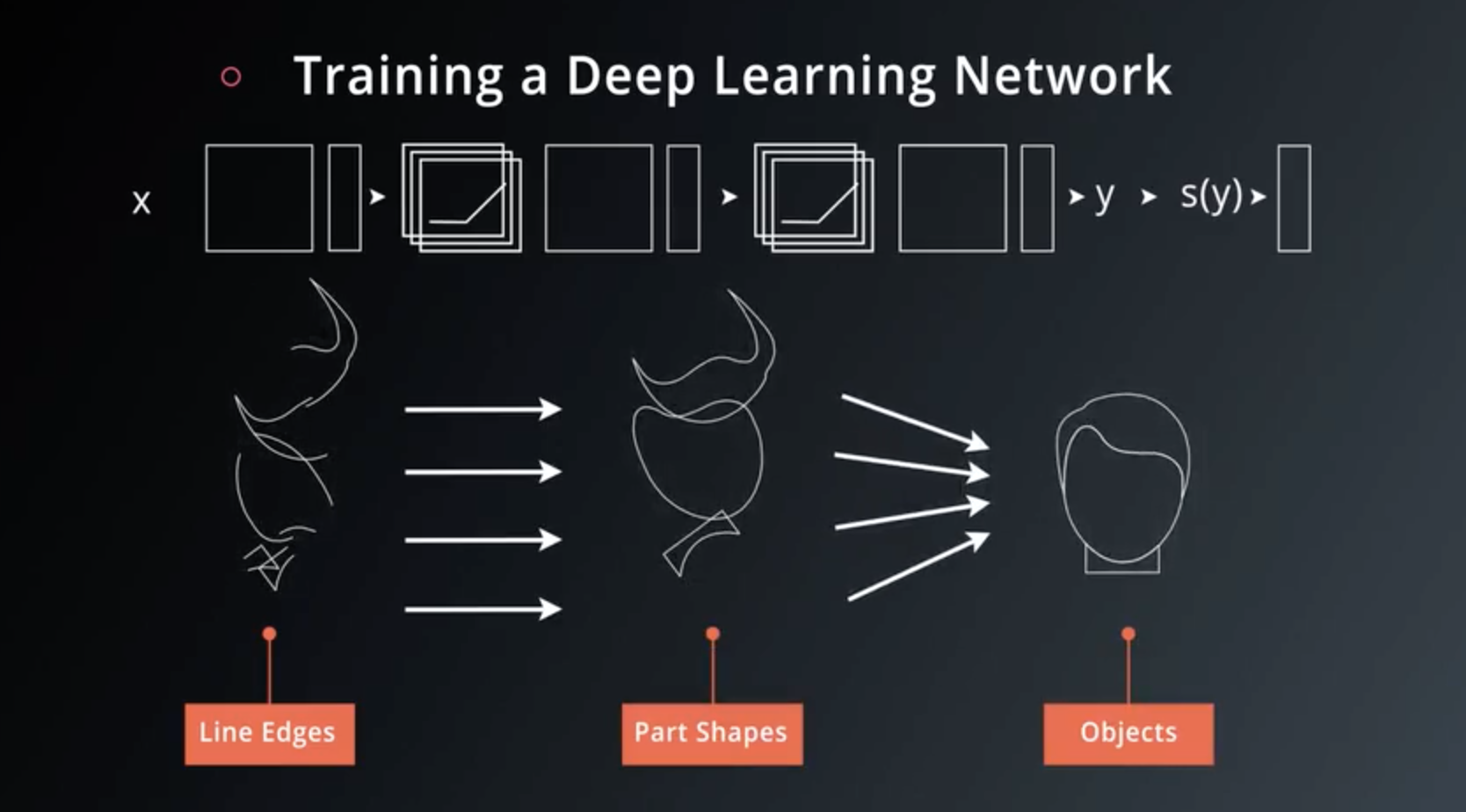
Training a Deep Neural Network
Save and Restore TensorFlow Models
- Training a model can take hours.
- Once you close your TensorFlow session, you lose all the trained weights and biases.
- Fortunately, TensorFlow gives you the ability to save your progress using a class called tf.train.Saver.
- This class provides the functionality to save any tf.Variable to your file system.
Saving Variables
Simple example of saving weights and bias Tensors.
The .ckpt extension stands for “checkpoint”.)
Code:
import tensorflow as tf
# The file path to save the data
save_file = './model.ckpt'
# Two Tensor Variables: weights and bias
weights = tf.Variable(tf.truncated_normal([2, 3]))
bias = tf.Variable(tf.truncated_normal([3]))
# Class used to save and/or restore Tensor Variables
saver = tf.train.Saver()
with tf.Session() as sess:
# Initialize all the Variables
sess.run(tf.global_variables_initializer())
# Show the values of weights and bias
print('Weights:')
print(sess.run(weights))
print('Bias:')
print(sess.run(bias))
# Save the model
saver.save(sess, save_file)
Out:
Weights:
[[ 0.03980349 -0.18252888 -0.08703336]
[ 0.07250483 1.19801128 0.47434121]]
Bias:
[-0.01317797 0.75998199 -0.8082276 ]
Loading Variables
Code:
# The file path to saved the data
save_file = './model.ckpt'
# Remove the previous weights and bias
tf.reset_default_graph()
# Two Variables: weights and bias
weights = tf.Variable(tf.truncated_normal([2, 3]))
bias = tf.Variable(tf.truncated_normal([3]))
# Class used to save and/or restore Tensor Variables
saver = tf.train.Saver()
with tf.Session() as sess:
# Load the weights and bias
saver.restore(sess, save_file)
# Show the values of weights and bias
print('Weight:')
print(sess.run(weights))
print('Bias:')
print(sess.run(bias))
Out:
INFO:tensorflow:Restoring parameters from ./model.ckpt
Weight:
[[ 0.03980349 -0.18252888 -0.08703336]
[ 0.07250483 1.19801128 0.47434121]]
Bias:
[-0.01317797 0.75998199 -0.8082276 ]
Save a Trained Model
Code: Define a Model
# Remove previous Tensors and Operations
tf.reset_default_graph()
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
learning_rate = 0.001
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
# Import MNIST data
mnist = input_data.read_data_sets('.', one_hot=True)
# Features and Labels
features = tf.placeholder(tf.float32, [None, n_input])
labels = tf.placeholder(tf.float32, [None, n_classes])
# Weights & bias
weights = tf.Variable(tf.random_normal([n_input, n_classes]))
bias = tf.Variable(tf.random_normal([n_classes]))
# Logits - xW + b
logits = tf.add(tf.matmul(features, weights), bias)
# Define loss and optimizer
cost = tf.reduce_mean(\
tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)\
.minimize(cost)
# Calculate accuracy
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
Code: Train that model, then save the weights:
import math
save_file = './train_model.ckpt'
batch_size = 128
n_epochs = 100
saver = tf.train.Saver()
# Launch the graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Training cycle
for epoch in range(n_epochs):
total_batch = math.ceil(mnist.train.num_examples / batch_size)
# Loop over all batches
for i in range(total_batch):
batch_features, batch_labels = mnist.train.next_batch(batch_size)
sess.run(
optimizer,
feed_dict={features: batch_features, labels: batch_labels})
# Print status for every 10 epochs
if epoch % 10 == 0:
valid_accuracy = sess.run(
accuracy,
feed_dict={
features: mnist.validation.images,
labels: mnist.validation.labels})
print('Epoch {:<3} - Validation Accuracy: {}'.format(
epoch,
valid_accuracy))
# Save the model
saver.save(sess, save_file)
print('Trained Model Saved.')
Out:
Epoch 0 - Validation Accuracy: 0.10700000077486038
Epoch 10 - Validation Accuracy: 0.23199999332427979
Epoch 20 - Validation Accuracy: 0.3959999978542328
Epoch 30 - Validation Accuracy: 0.4957999885082245
Epoch 40 - Validation Accuracy: 0.5569999814033508
Epoch 50 - Validation Accuracy: 0.6083999872207642
Epoch 60 - Validation Accuracy: 0.6435999870300293
Epoch 70 - Validation Accuracy: 0.6665999889373779
Epoch 80 - Validation Accuracy: 0.6868000030517578
Epoch 90 - Validation Accuracy: 0.7038000226020813
Trained Model Saved.
Load a Trained Model
Code:
saver = tf.train.Saver()
# Launch the graph
with tf.Session() as sess:
saver.restore(sess, save_file)
test_accuracy = sess.run(
accuracy,
feed_dict={features: mnist.test.images, labels: mnist.test.labels})
print('Test Accuracy: {}'.format(test_accuracy))
Out:
INFO:tensorflow:Restoring parameters from ./train_model.ckpt
Test Accuracy: 0.7208999991416931
Finetuning
- Sometimes you might want to adjust, or “finetune” a model that you have already trained and saved.
- However, loading saved Variables directly into a modified model can generate errors. Let’s go over how to avoid these problems.
Naming Error
- TensorFlow uses a string identifier for Tensors and Operations called
name.- If a
nameis not given, TensorFlow will create one automatically. - TensorFlow will give the first node the name
<Type>, and then give the name<Type>_<number>for the subsequent nodes.
- If a
Let’s see how this can affect loading a model with a different order of weights and bias:
Code:
import tensorflow as tf
# Remove the previous weights and bias
tf.reset_default_graph()
save_file = './model.ckpt'
# Two Tensor Variables: weights and bias
weights = tf.Variable(tf.truncated_normal([2, 3]))
bias = tf.Variable(tf.truncated_normal([3]))
saver = tf.train.Saver()
# Print the name of Weights and Bias
print('Save Weights: {}'.format(weights.name))
print('Save Bias: {}'.format(bias.name))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.save(sess, save_file)
# Remove the previous weights and bias
tf.reset_default_graph()
# Two Variables: weights and bias
bias = tf.Variable(tf.truncated_normal([3]))
weights = tf.Variable(tf.truncated_normal([2, 3]))
saver = tf.train.Saver()
# Print the name of Weights and Bias
print('Load Weights: {}'.format(weights.name))
print('Load Bias: {}'.format(bias.name))
with tf.Session() as sess:
# Load the weights and bias - ERROR
saver.restore(sess, save_file)
Out:
Save Weights: Variable:0
Save Bias: Variable_1:0
Load Weights: Variable_1:0
Load Bias: Variable:0
...
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match.
...
- You’ll notice that the name properties for
weightsandbiasare different than when you saved the model. - This is why the code produces the
Assign requires shapes of both tensors to matcherror. - The code
saver.restore(sess, save_file)is trying to loadweightdata intobiasandbiasdatainto weights.
Instead of letting TensorFlow set the name property, let’s set it manually:
Code:
import tensorflow as tf
tf.reset_default_graph()
save_file = './model.ckpt'
# Two Tensor Variables: weights and bias
weights = tf.Variable(tf.truncated_normal([2, 3]), name='weights_0')
bias = tf.Variable(tf.truncated_normal([3]), name='bias_0')
saver = tf.train.Saver()
# Print the name of Weights and Bias
print('Save Weights: {}'.format(weights.name))
print('Save Bias: {}'.format(bias.name))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.save(sess, save_file)
# Remove the previous weights and bias
tf.reset_default_graph()
# Two Variables: weights and bias
bias = tf.Variable(tf.truncated_normal([3]), name='bias_0')
weights = tf.Variable(tf.truncated_normal([2, 3]) ,name='weights_0')
saver = tf.train.Saver()
# Print the name of Weights and Bias
print('Load Weights: {}'.format(weights.name))
print('Load Bias: {}'.format(bias.name))
with tf.Session() as sess:
# Load the weights and bias - No Error
saver.restore(sess, save_file)
print('Loaded Weights and Bias successfully.')
Out:
Save Weights: weights_0:0
Save Bias: bias_0:0
Load Weights: weights_0:0
Load Bias: bias_0:0
INFO:tensorflow:Restoring parameters from ./model.ckpt
Loaded Weights and Bias successfully.
Regularization
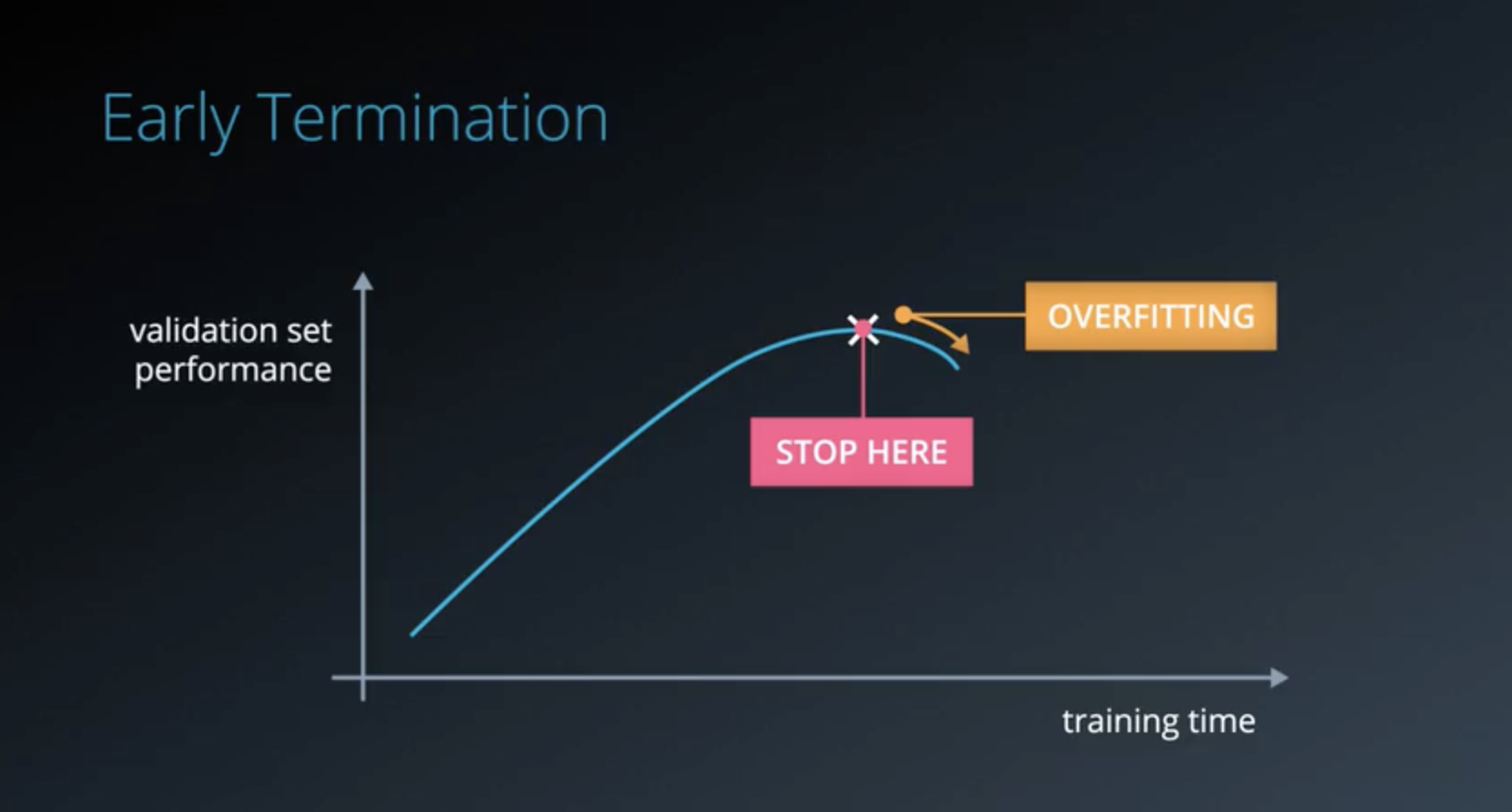
- Early Termination
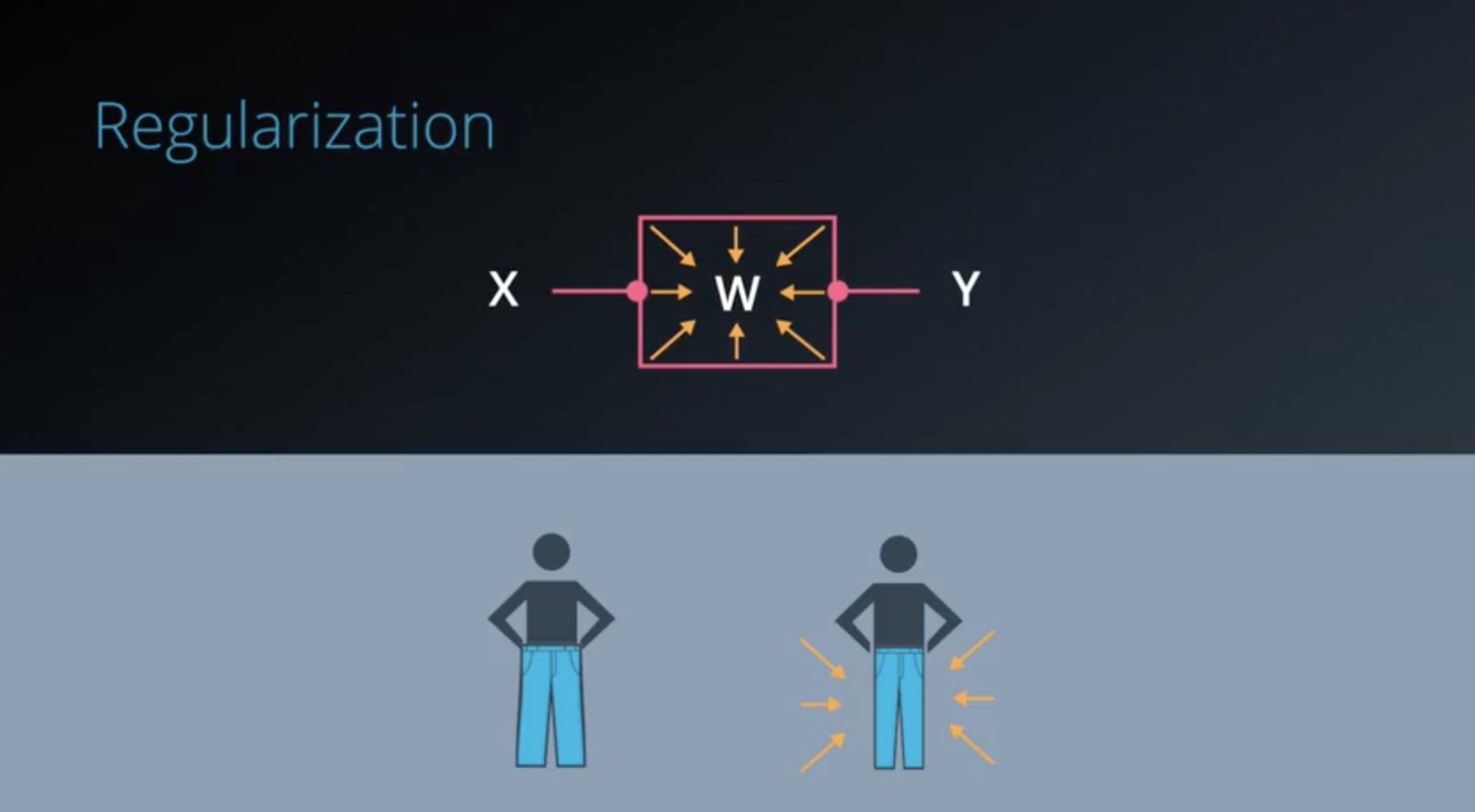
- Regularization
- Regularizing means applying artificial constraints on your network.
- That implicitly reduce the number of free parameters.
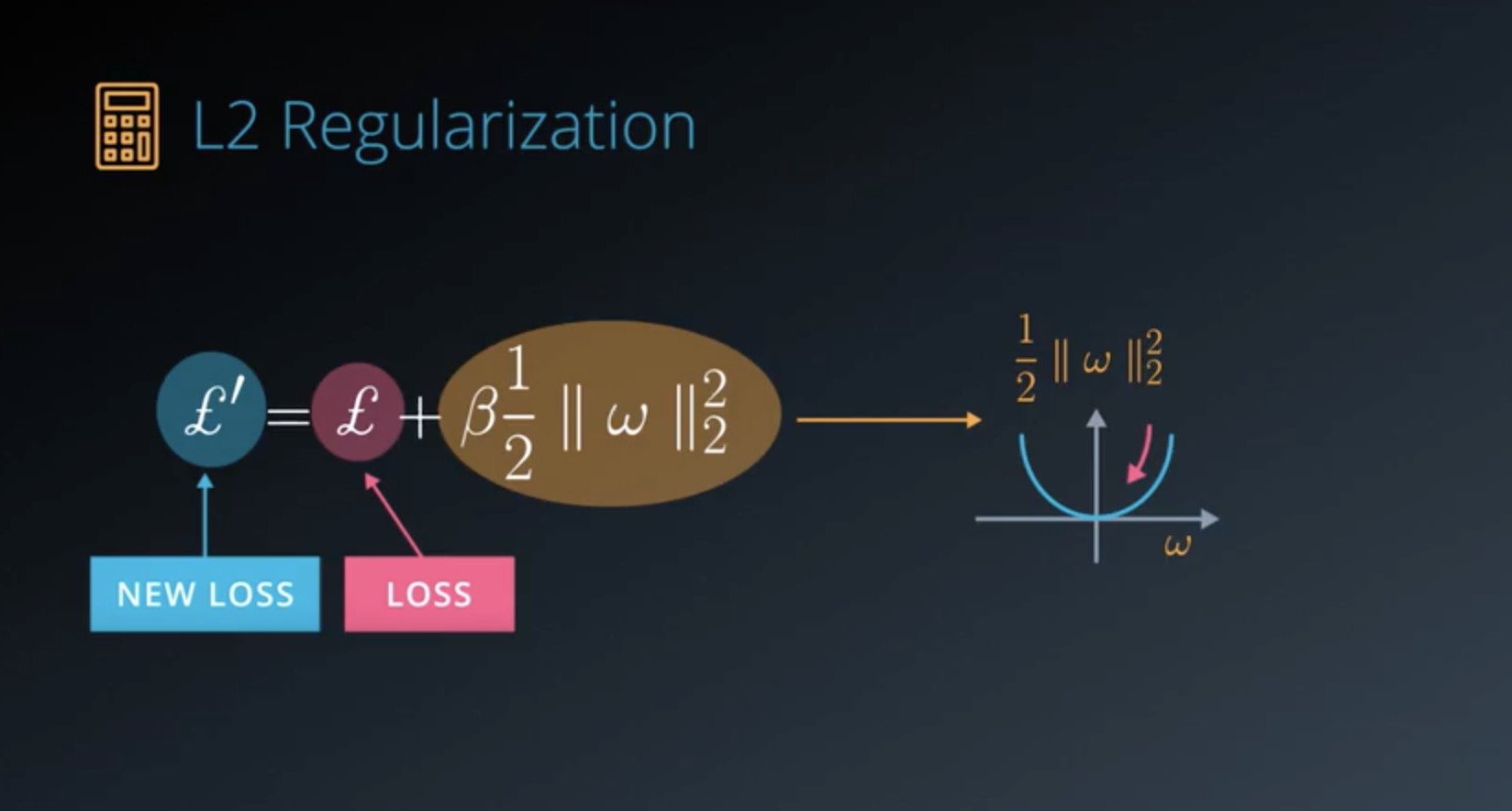
- In Deep Learning,
L2 Regularization.- Add another term to
loss, which penalizes large weights. - Adding
L2 normon your weights.
- Add another term to
Dropout
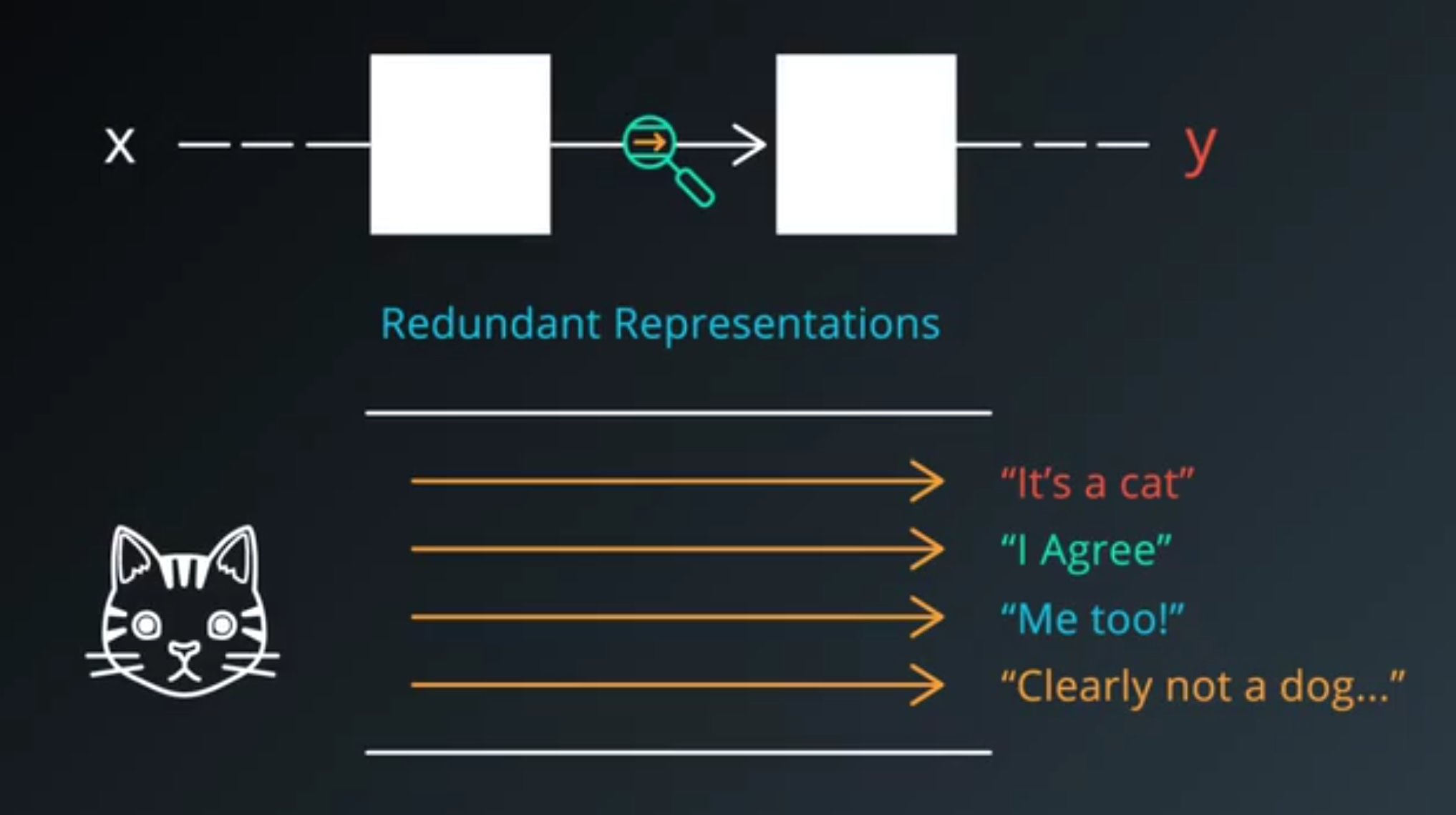
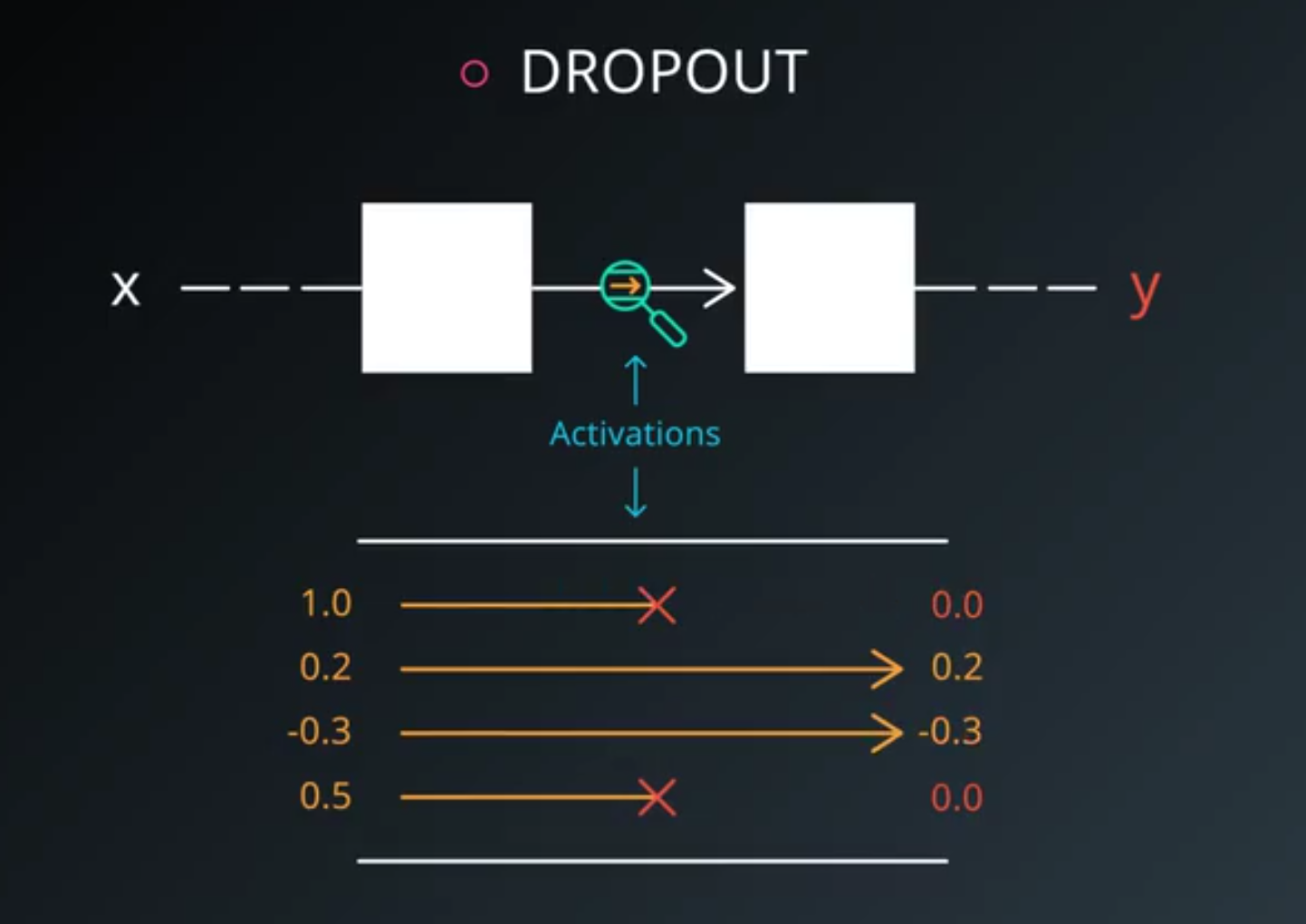
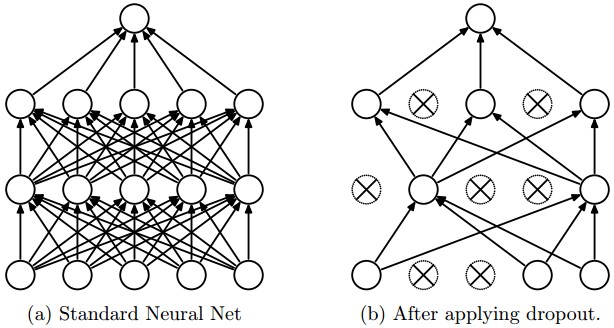
- Dropout is a regularization technique for reducing overfitting.
- The technique temporarily drops units (artificial neurons) from the network.
- Along with all of those units’ incoming and outgoing connections.
- Your network can never rely on any given activation to be present.
- Because they might be squashed at any given moment.
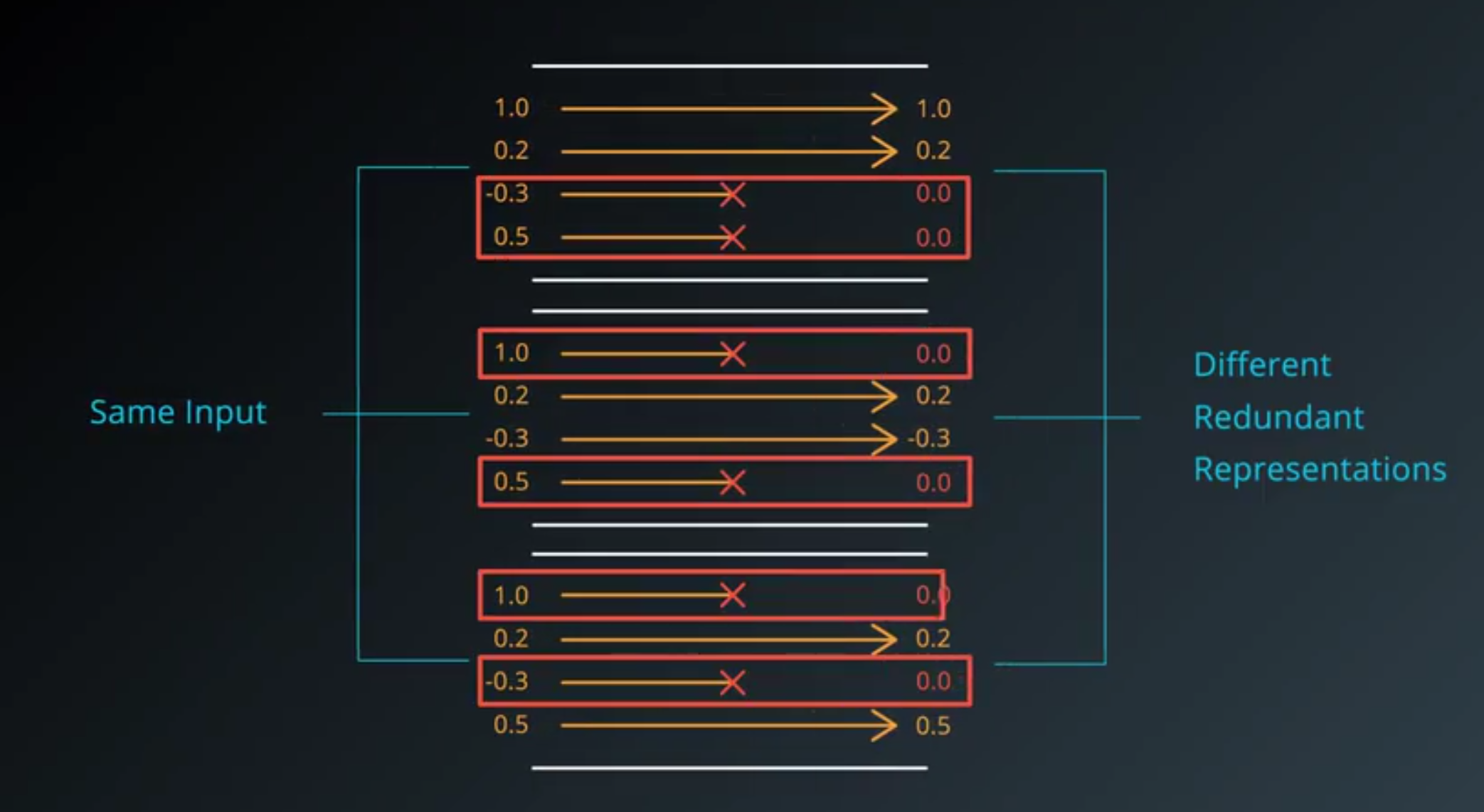
- It is forced to learn a redundant represantion for everything to make sure that at least some of the information remains.
Dropouts in Tensorflow
keep_proballows you to adjust the number of units to drop.- In order to compensate for dropped units,
tf.nn.dropout()multiplies all units that are kept (i.e. not dropped) by1/keep_prob. - During training, a good starting value for
keep_probis0.5. - During testing, use a
keep_probvalue of1.0to keep all units and maximize the power of the model.
Code:
import tensorflow as tf
hidden_layer_weights = [
[0.1, 0.2, 0.4],
[0.4, 0.6, 0.6],
[0.5, 0.9, 0.1],
[0.8, 0.2, 0.8]]
out_weights = [
[0.1, 0.6],
[0.2, 0.1],
[0.7, 0.9]]
# Weights and biases
weights = [
tf.Variable(hidden_layer_weights),
tf.Variable(out_weights)]
biases = [
tf.Variable(tf.zeros(3)),
tf.Variable(tf.zeros(2))]
# Input
features = tf.Variable([[0.0, 2.0, 3.0, 4.0], [0.1, 0.2, 0.3, 0.4], [11.0, 12.0, 13.0, 14.0]])
# TODO: Create Model with Dropout
keep_prob = tf.placeholder(tf.float32)
hidden_layer = tf.add(tf.matmul(features, weights[0]), biases[0])
hidden_layer = tf.nn.relu(hidden_layer)
hidden_layer = tf.nn.dropout(hidden_layer, keep_prob)
logits = tf.add(tf.matmul(hidden_layer, weights[1]), biases[1])
# TODO: Print logits from a session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(logits, feed_dict={keep_prob: 0.5}))
[[ 6.57999945 8.45999908]
[ 0.30800003 0.7700001 ]
[ 14.28000069 33.09999847]]
- Forcing your network to learn redundant representations might sound very inefficient.
- But in practice, it makes things more robust, and prevent overfitting.
- If Dropouts* doesn’t work for you, you should probably using **bigger network.