Hyperparameters
Outline:
- Introduction
- Learning Rate
- Minibatch
- Number of Training Iterations
- Number of Hidden Units Layers
- RNN Hyperparameters
- Sources and References
Introduction
- Hyperparameter
- Variable that we need to set before applying a learning algorithm to a data set.
- Challenge
- There are no magic numbers that work everywhere.
- The best numbers depend on each task and each dataset.
Hyperparameters categories
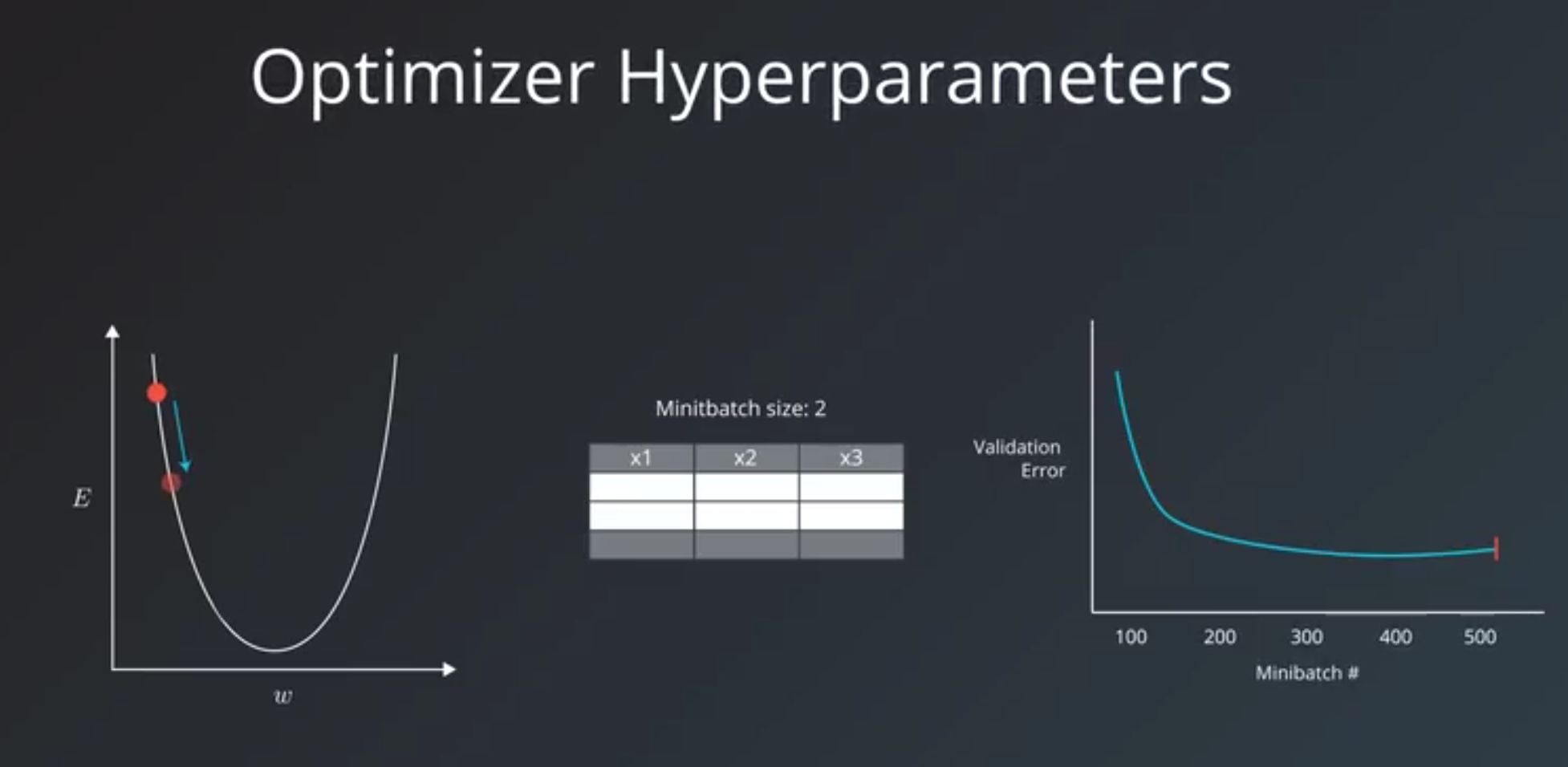
1. Optimizer Hyperparameters
- related more the optimization and training process than to the model itself.
learning rate, theminibatch size, and the number of training iterations orEpochs.
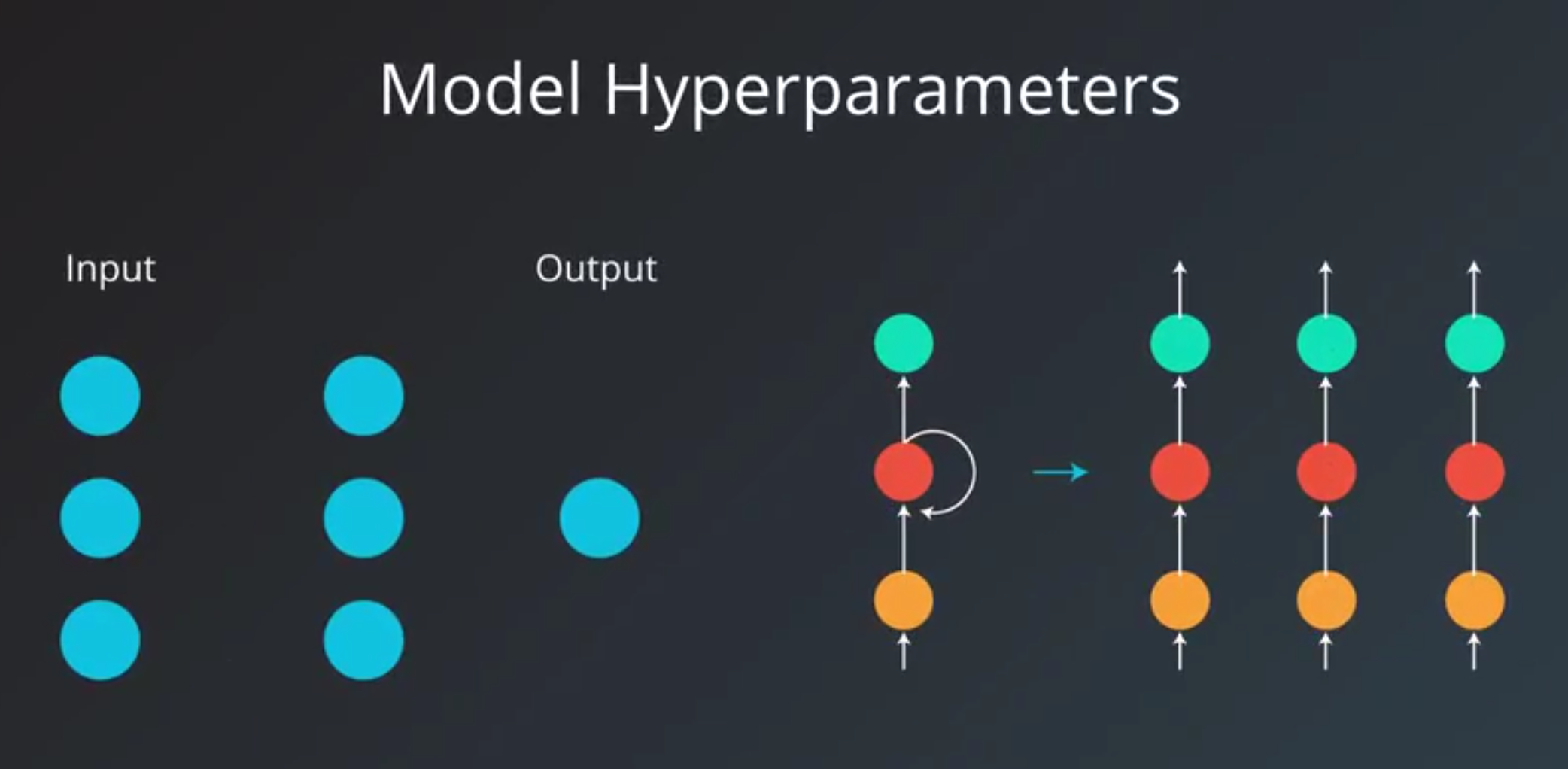
2. Model Hyperparameters
- more involved in the structure of the model
- the number of layers and hidden units and model specific hyperparameters for architectures like RNNs.
Learning Rate
- Good Starting Points
- then a good starting point is usually
0.01 - these are the usual suspects of learning rates
- then a good starting point is usually
- Gradient
- Calculating the gradient would tell us which direction to go to decrease the error.
- the gradient will point out which direction to go
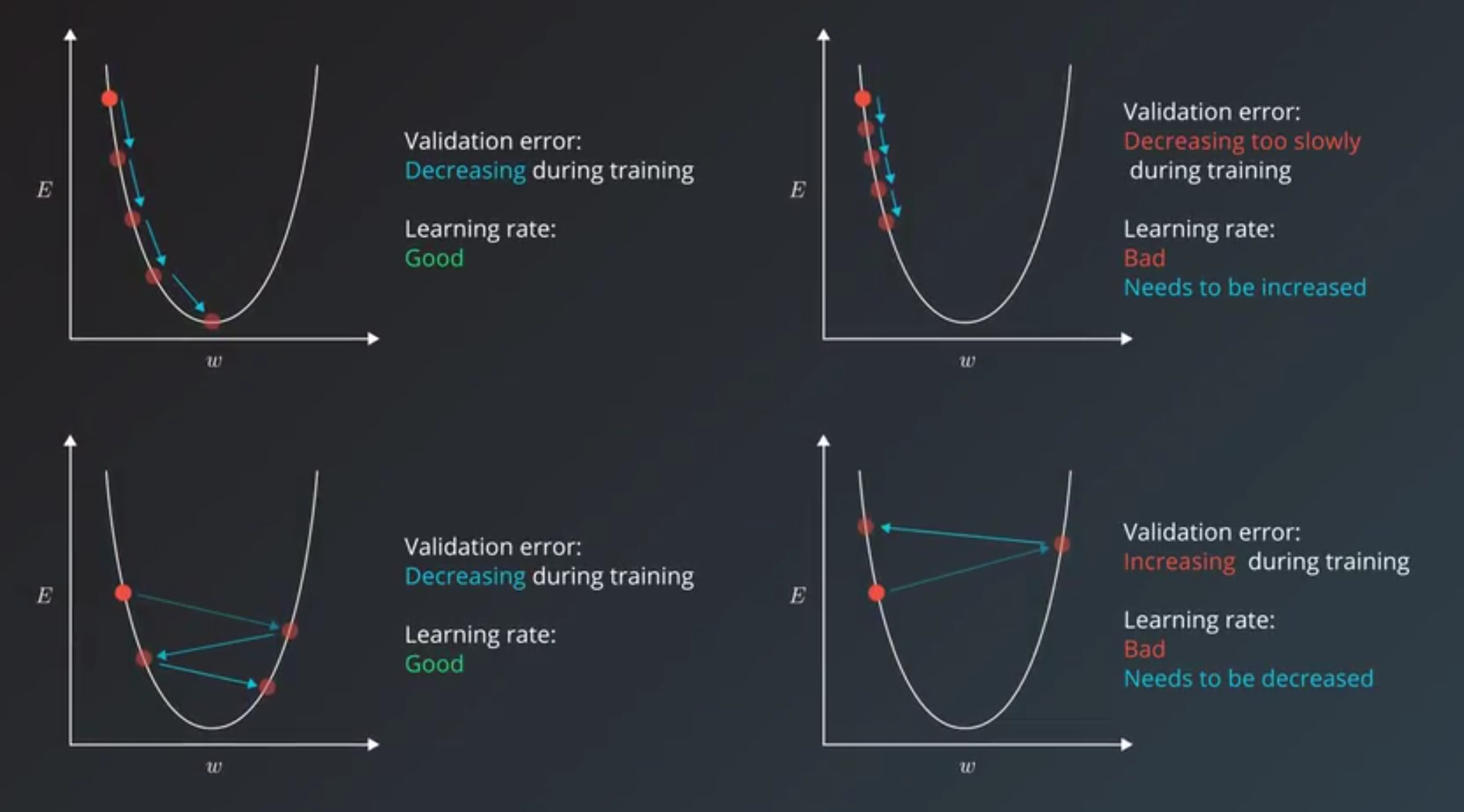
- Learning Rate
- Is the multiplier we use to push the weight towards the right direction.
Learning Rate Decay
- It would be stuck oscillating between values that still have a better error value than when we started training, but are not the best values possible for the model.
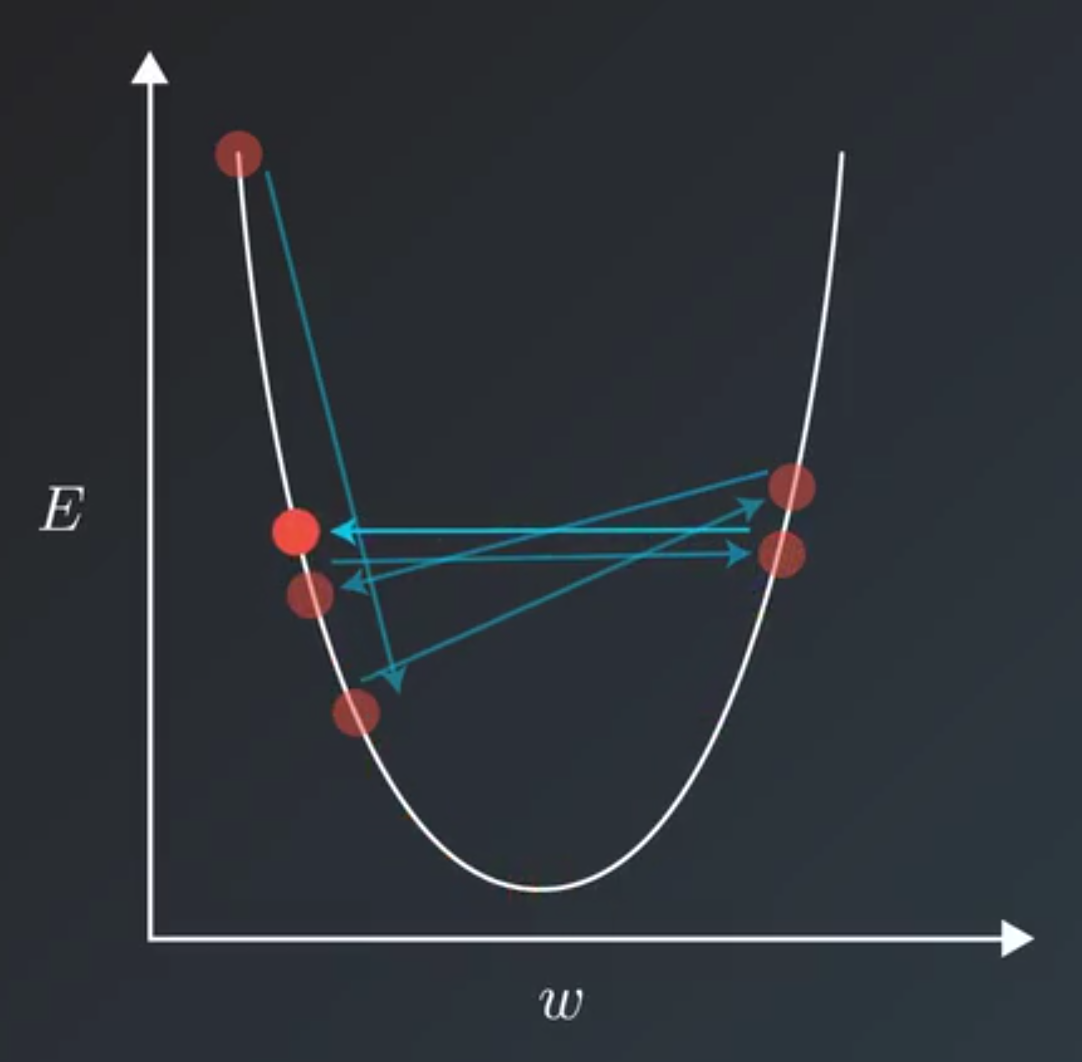
- Intuitive ways to do this can be by decreasing the learning rate linearly.
- also decrease the learning rate exponentially
- So, for example we’d multiply the learning rate by 0.1 every 8 epochs for example.
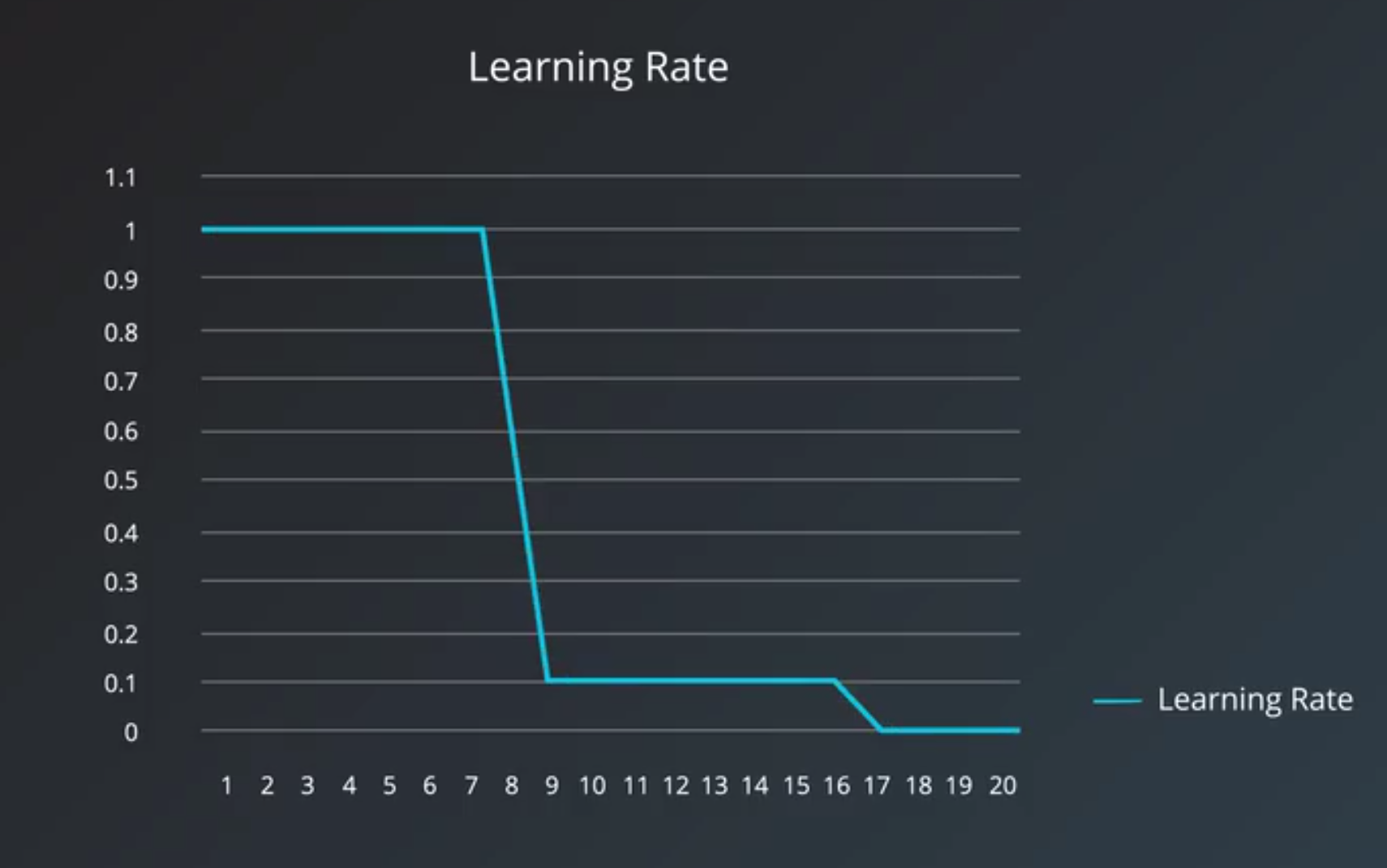
Adaptive learning rate
- There are more clever learning algorithms that have an adaptive learning rate.
- These algorithms adjust the learning rate based on what the learning algorithm knows about the problem and the data that it’s seen so far.
- This means not only decreasing the learning rate when needed,
- but also increasing it when it appears to be too low.
- Adaptive Learning Optimizers
Minibatch
- Online(Stochastic) training
- fit a single example of data set to the model during a training step
- Batch training
- the entire dataset to the training step
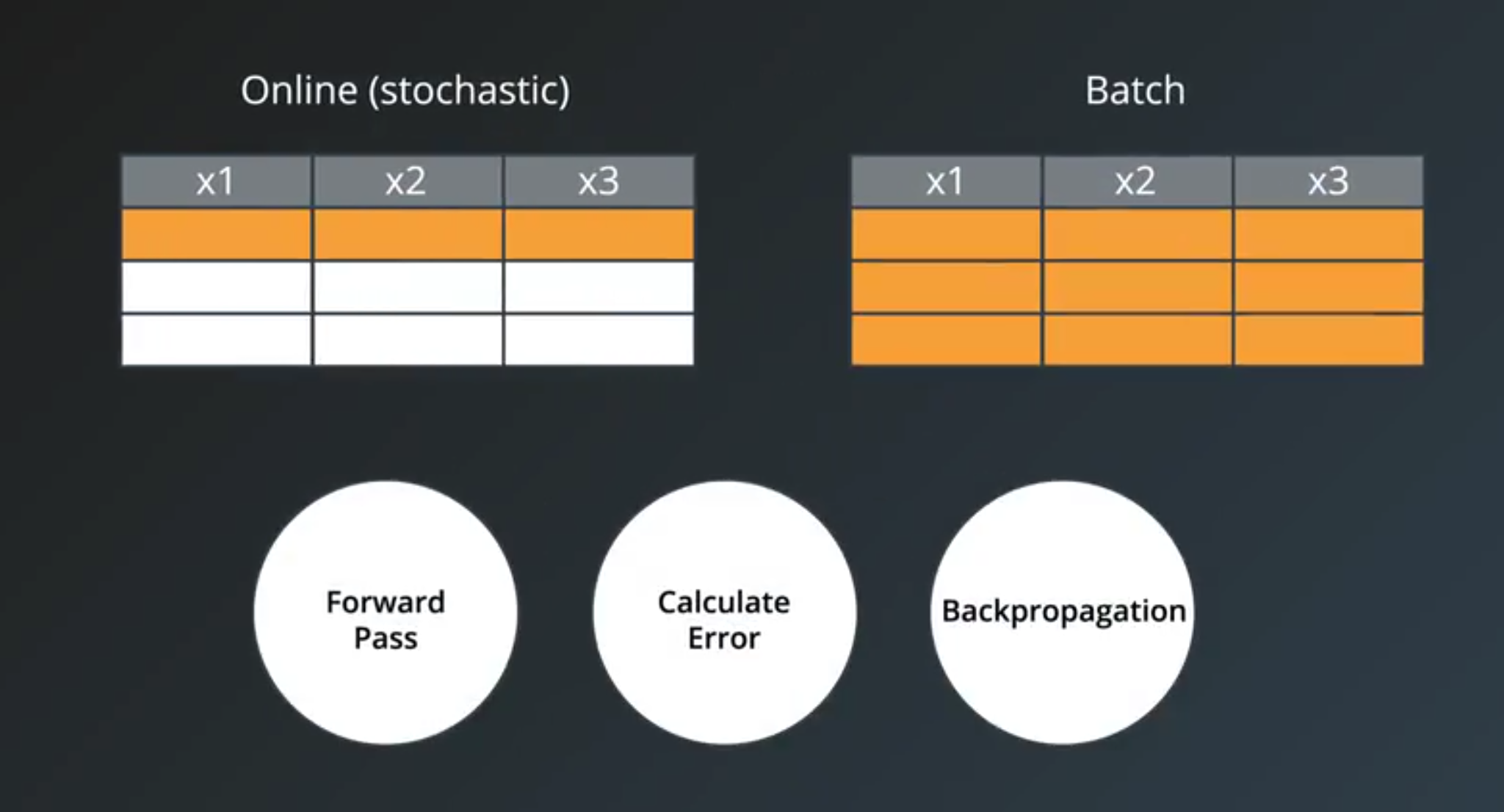
- Minibatch training
- online training is when the minibatch size is 1
- batch training is when the minibatch size is the same as the number of examples in the training set
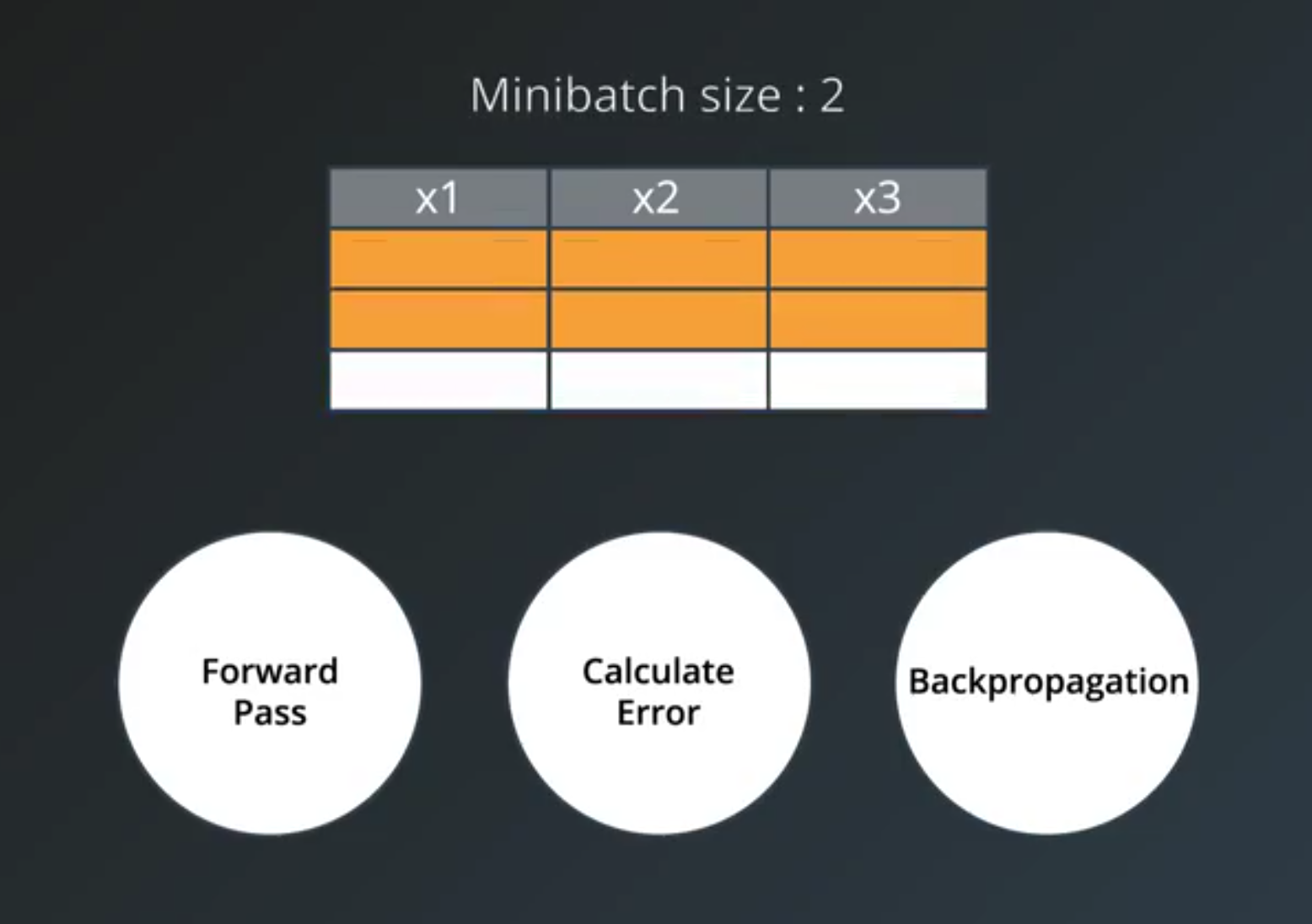
- Good Starting Points
- The recommended starting values:
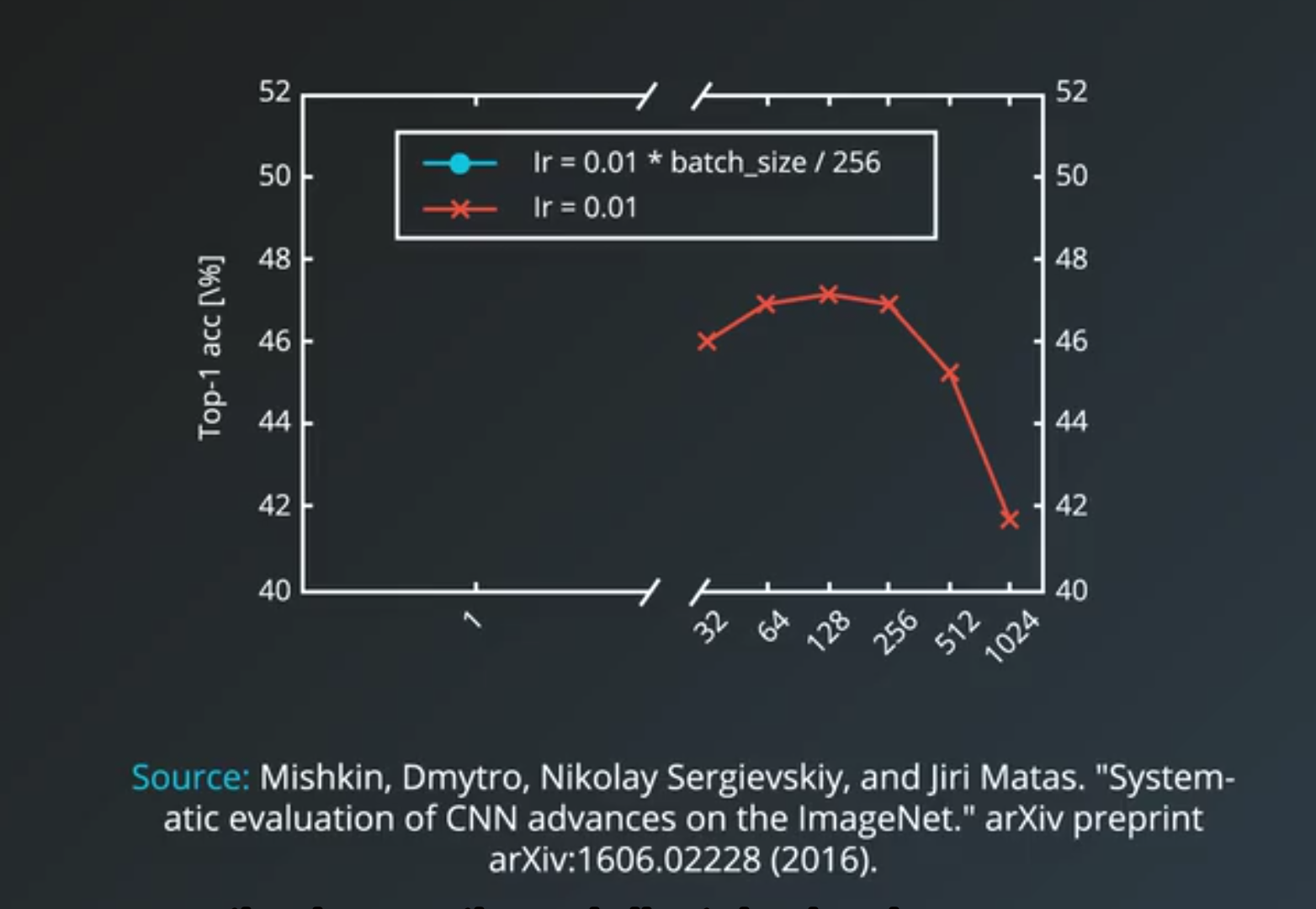
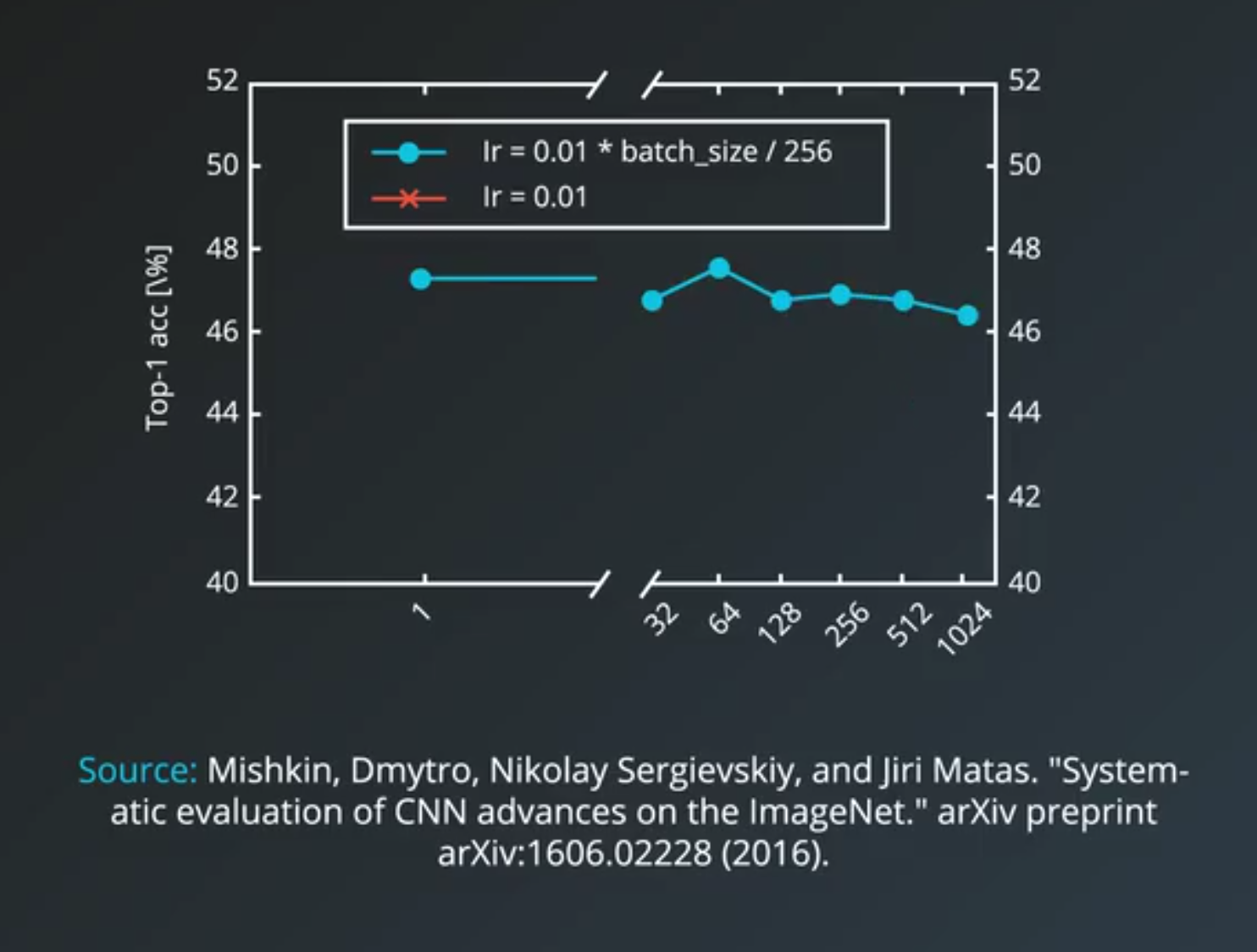
32often being a good candidate.- larger minibatch size
- allows computational boost that utilizes matrix multiplication in the training calculations
- but that comes at the expense of needing more memory for the training process and generally more computational resources.
- Some out of memory errors in Tensorflow can be eliminated by decreasing the minibatch size.
- small minibatch size
- have more noise in their error calculations and this noise is often helpful in preventing the training process from stopping at local minima on curve
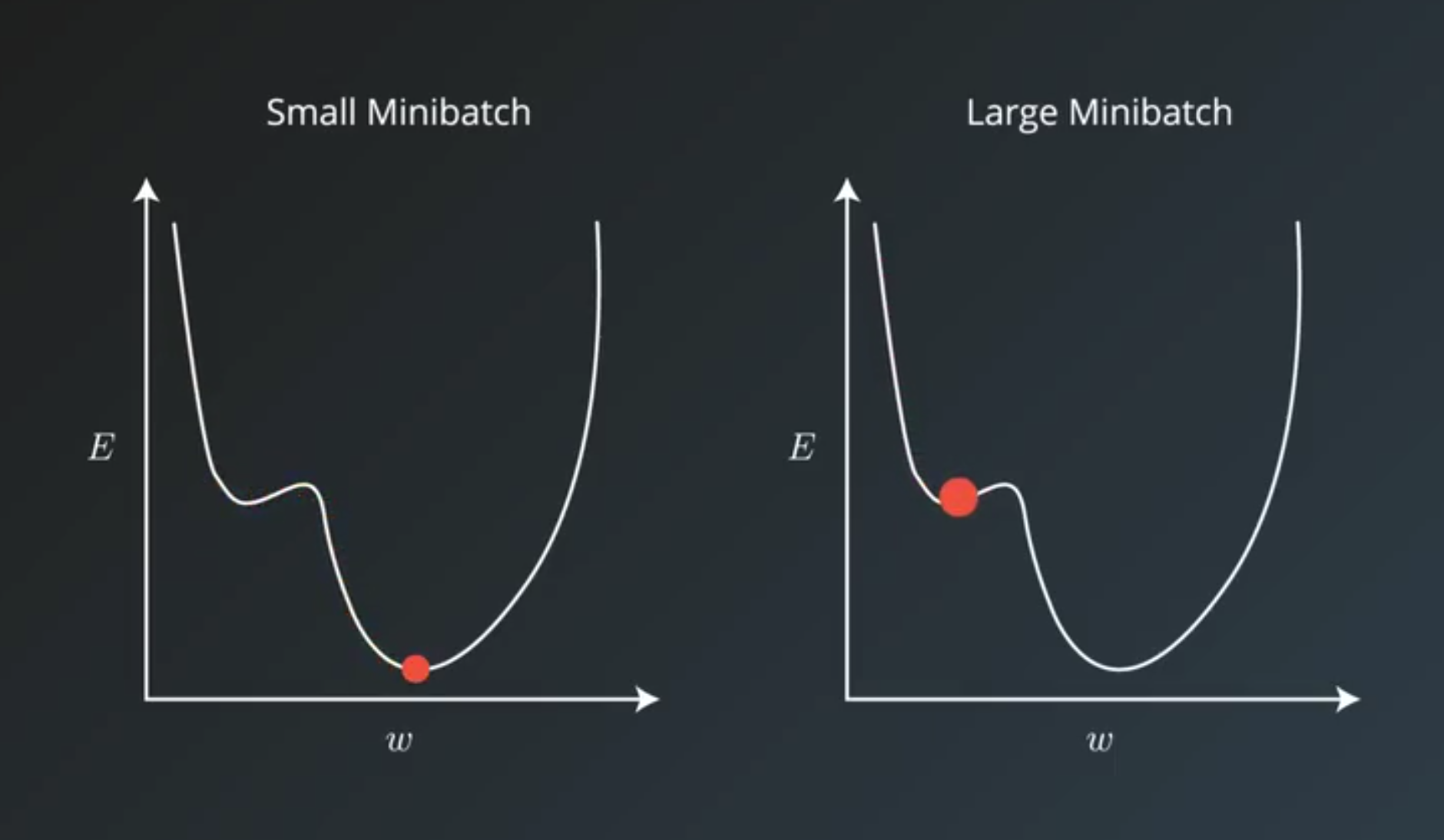
- have more noise in their error calculations and this noise is often helpful in preventing the training process from stopping at local minima on curve
- experimental result
- too small could be too slow,
- too large could be computationally taxing and could result in worse accuracy.
- And 32 to 256 are potentially good starting values for you to experiment with.
Number of Training Iterations
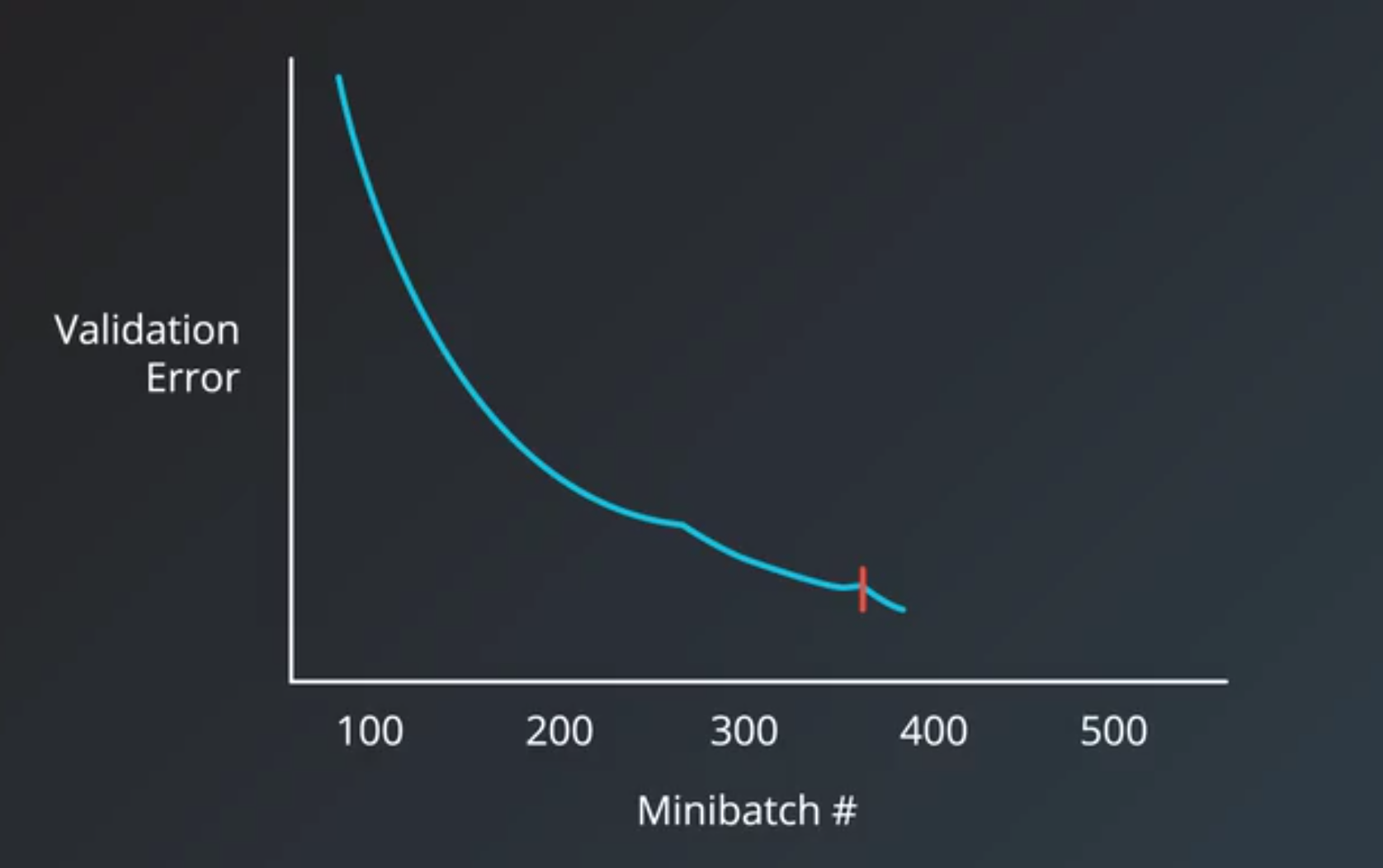
- To choose the right number of iterations or number of epochs for our training step,
- the metric we should have our eyes on is the validation error.
- Early Stopping
- determine when to stop training a model
- roughly works by monitoring the validation error and stopping the training when it stops decreasing.
Number of Hidden Units Layers
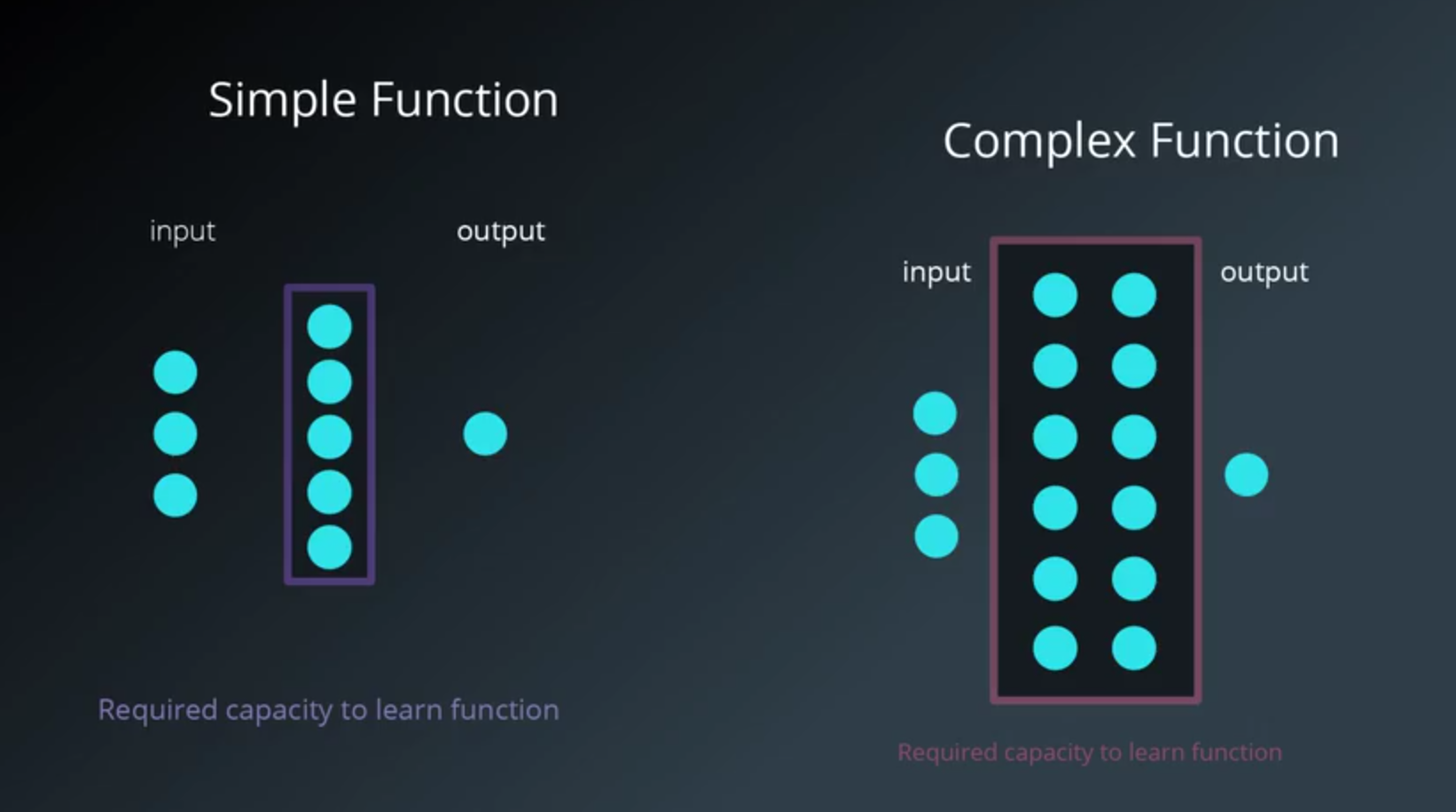
- The number and architecture of the hidden units is the main measure for a model’s learning capacity.
- Provide the model with too much capacity
- it might tend to overfit and just try to memorize the training set.
- meaning that the training accuracy is much better than the validation accuracy
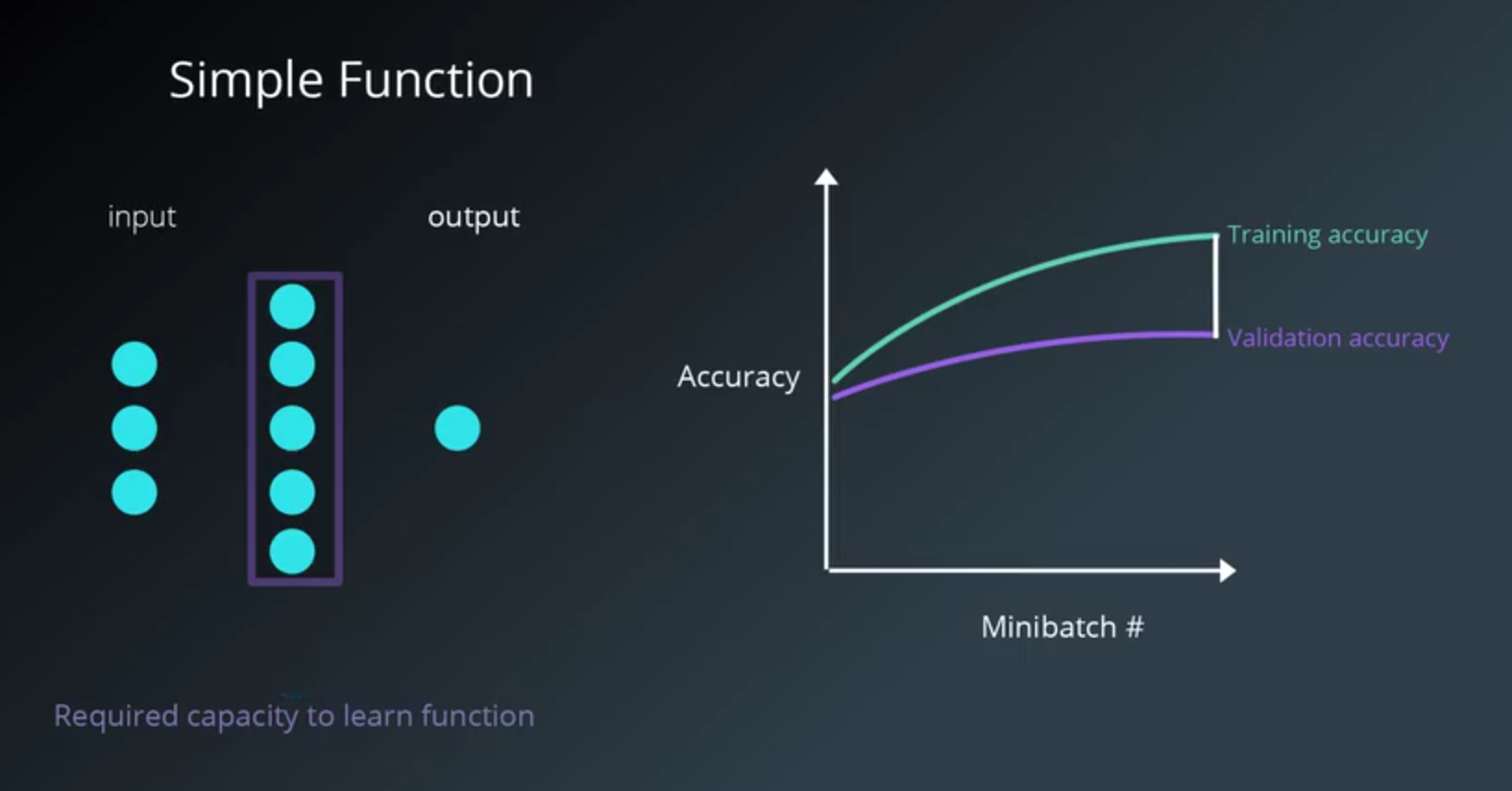
- Might want to try to decrease the number of hidden units
- Utilize regularization techniques like dropouts or L2 regularization

- Provide the model with too much capacity
The number of hidden units
- The more hidden units is the better
- a little larger than the ideal number is not a problem
- much larger value can often lead to the model overfitting
- If model is not training
- add more hidden units and track validation error
- keep adding hidden units until the validation starts getting worse.
- Another heuristic involving the first hidden layer
- larger than the number of the inputs has been observed to be beneficial in a number of tests
The number of layers
- It’s often the case that a three-layer neural net will outperform a two-layer net
- but going even deeper is rarely helps much more.
- The exception
- Convolutional neural networks where the deeper they are, the better they perform.
RNN Hyperparameters
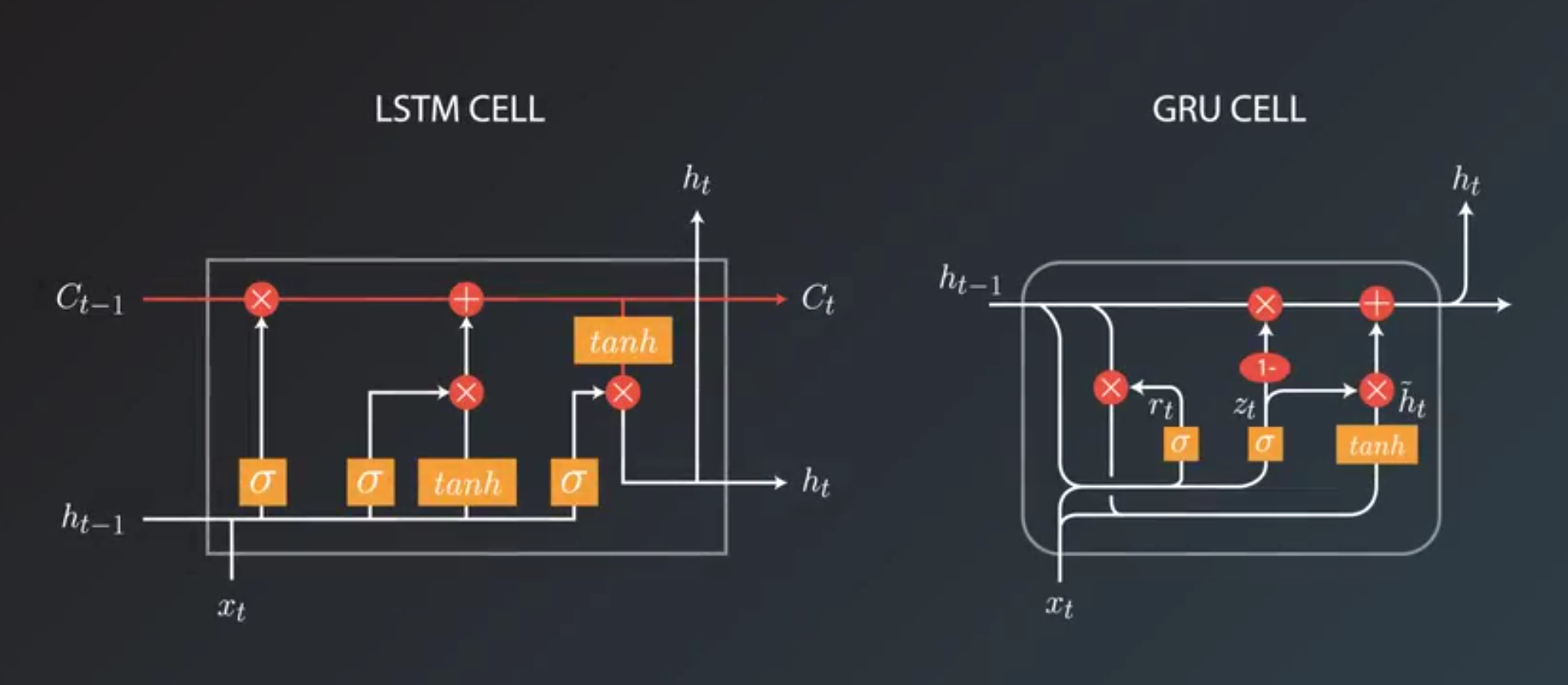
- Two main choices we need to make when we want to build RNN
- choosing cell type
- long short-term memory cell
- vanilla RNN cell
- gated recurrent unit cell
- how deep the model is
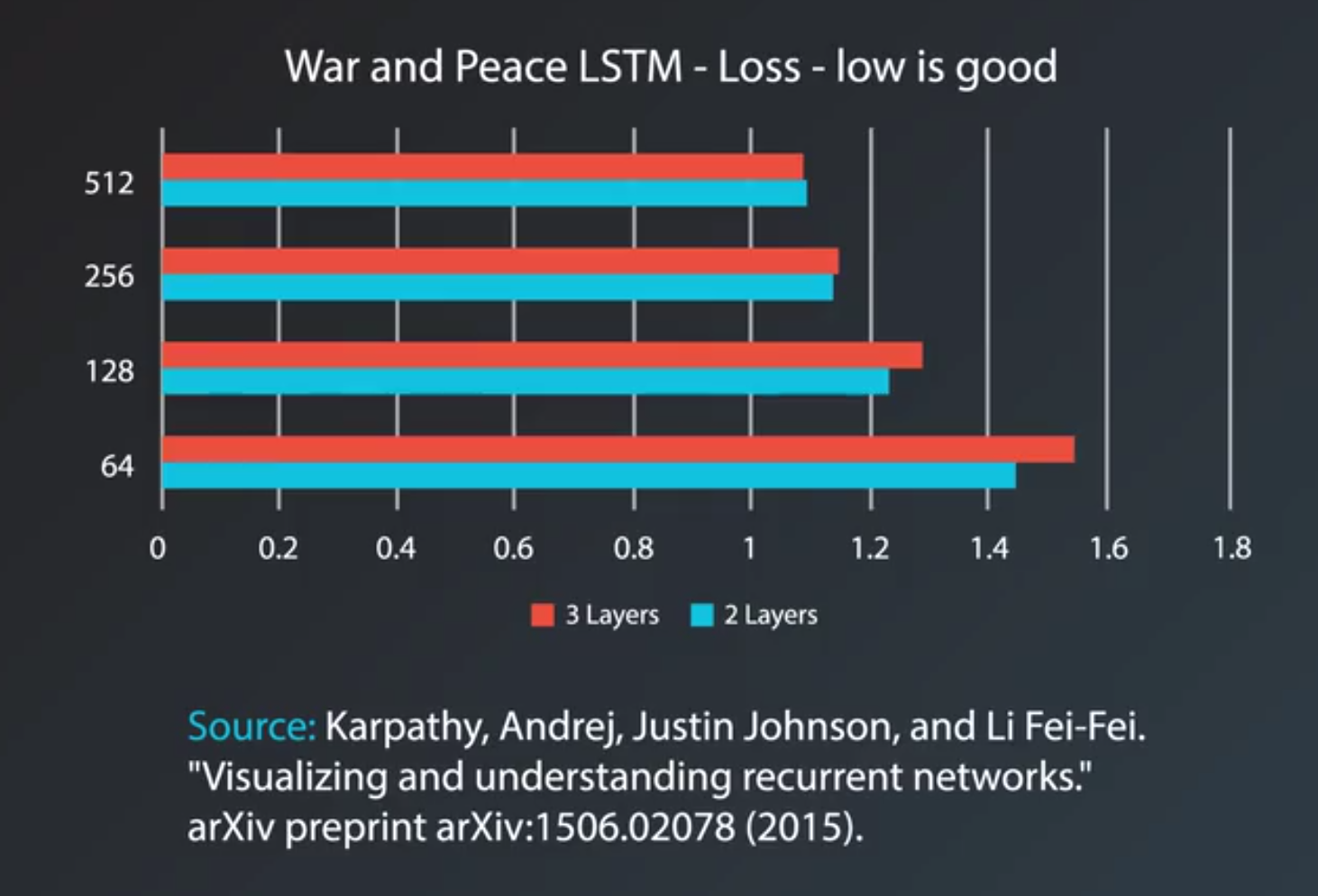
- choosing cell type
- In practice, LSTMs and GRUs perform better than vanilla RNNs
- While LSTMs seem to be more commonly used
- It really depends on the task and the dataset.
- While LSTMs seem to be more commonly used
Sources and References
If you want to learn more about hyperparameters, these are some great resources on the topic:
- Practical recommendations for gradient-based training of deep architectures by Yoshua Bengio
- Deep Learning book - chapter 11.4: Selecting Hyperparameters by Ian Goodfellow, Yoshua Bengio, Aaron Courville
- Neural Networks and Deep Learning book - Chapter 3: How to choose a neural network’s hyper-parameters? by Michael Nielsen
- Efficient BackProp (pdf) by Yann LeCun
More specialized sources:
- How to Generate a Good Word Embedding? by Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao
- Systematic evaluation of CNN advances on the ImageNet by Dmytro Mishkin, Nikolay Sergievskiy, Jiri Matas
- Visualizing and Understanding Recurrent Networks by Andrej Karpathy, Justin Johnson, Li Fei-Fei