Semi-Supervised Learning
Outline:
Semi-Supervised Classification with GANs
- A much more generally useful application of GANs is
- semi-supervised learning, where we actually improve the performance of a classifier using a GAN.
- Many more current products and services use classification than generation.
- Object recognition models
- based on deep learning often achieve superhuman accuracy after they have been trained.
- Modern deep learning algorithms are not yet anywhere near human efficiency during learning.
- Object recognition models
- People are able to learn from very few examples provided by a teacher.
- But that’s probably because people also have all kinds of sensory experience that doesn’t come with labels.
- We don’t receive labels for most of our experiences.
- And we have a lot of experiences that don’t resemble anything
- that a modern deep learning algorithm gets to see in its training set.
- One path to improving the learning efficiency of deep learning models is semi-supervised learning.
- Semi-supervised learning
- can learn from the labeled examples like usual.
- But it can also get better at classification, by studying unlabelled examples
- even though those examples have no class label.
- Usually, it is much easier and cheaper to obtain unlabeled data than to obtain labeled data.

- To do semi-supervised classification with GANs
- we’ll need to set up the GAN to work as a classifier.
- GANs contain two models, the generator and the discriminator.
- Usually we train both and then throw the discriminator away at the end of training.
- We usually only care about using the generator to create samples.

- The discriminator
- For semi-supervised learning focus on the discriminator rather than the generator.
- We’ll extend the discriminator to be our classifier
- and use it to classify new data after we’re done training it.
- We can actually throw away the generator, unless we also want to generate images.
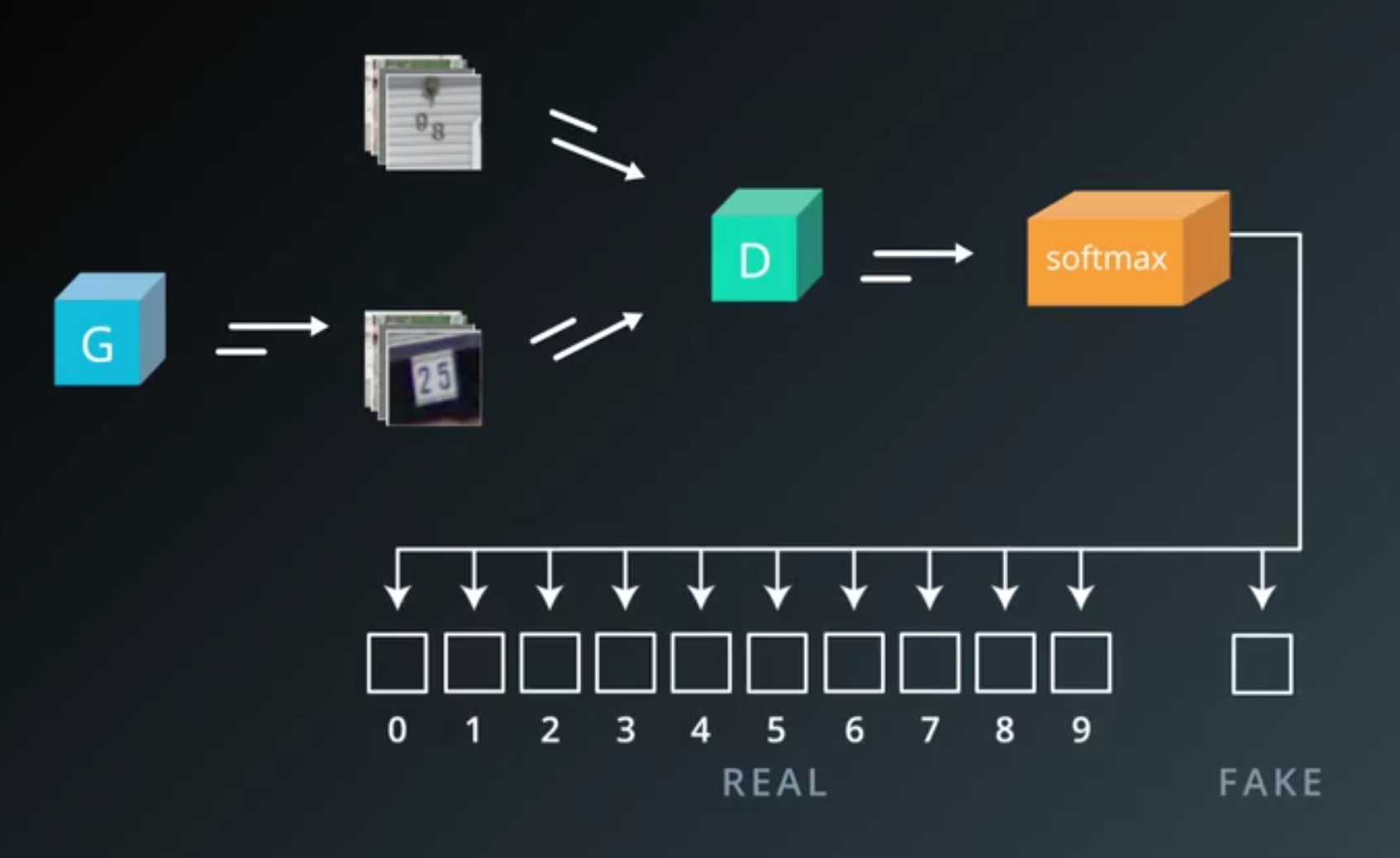
- So far a discriminator net with one sigmoid output, gives us the probability
- We can turn this into a softmax with two outputs,
- one corresponding to the real class
- one corresponding to the fake class
- Training
- Now we can train the model using the sum of two costs.
- For the examples that have labels, we can use the regular supervised cross entropy cost.
- For all of the other examples and also for fake samples from the generator, we can add the GAN cost.
- To get the probability that the input is real,
- we just sum over the probabilities for all the real classes.
- Normal classifiers can learn only on labeled images.
- This new setup can learn on
- labeled images
- real unlabeled images
- and even fake images from the generator.
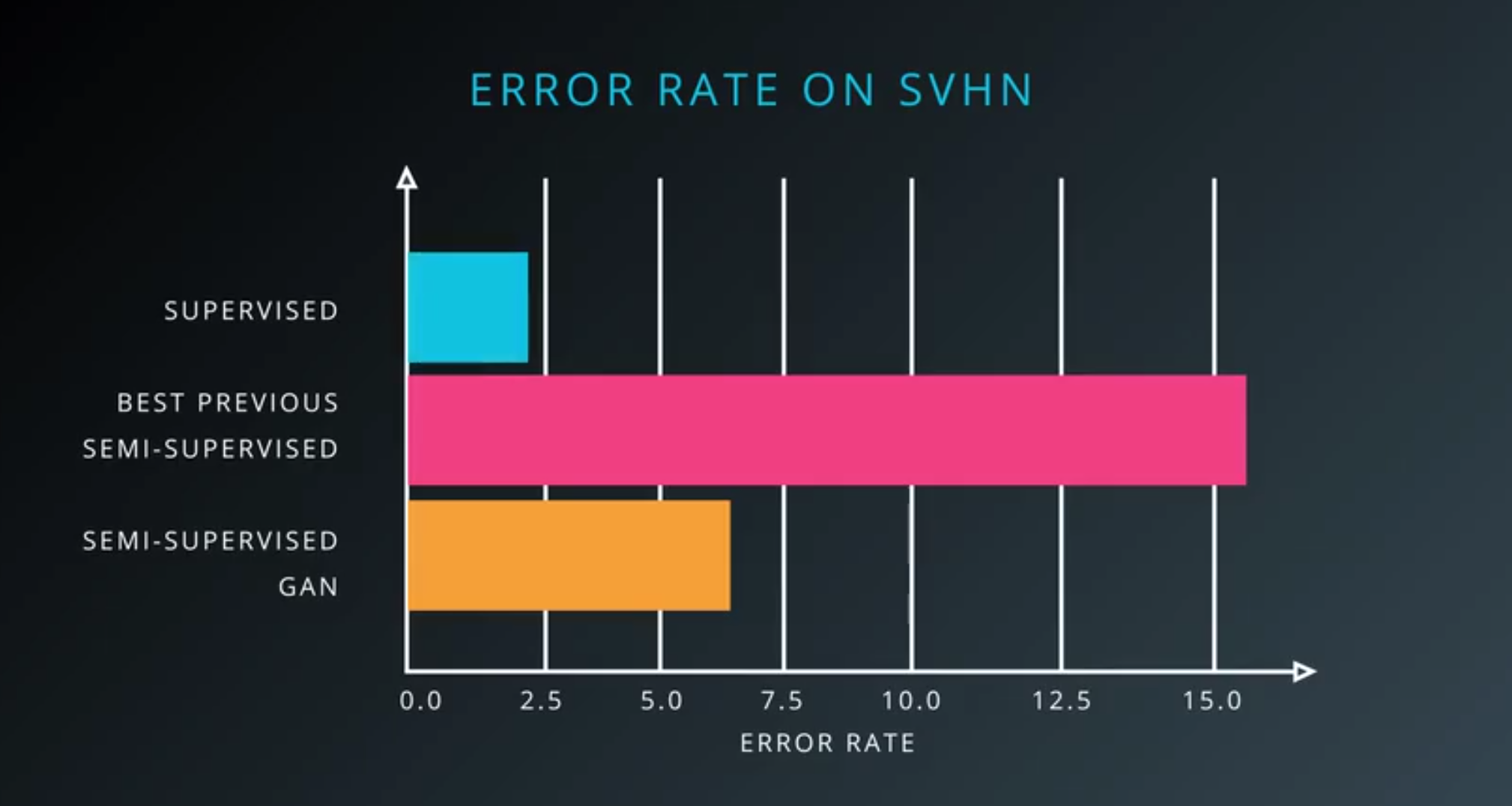
- Altogether this results in very low error on the test set
- because there are so many different sources of information even without using many labeled examples.
- To get this to work really well, we need one more trick called feature matching.

- Feature matching
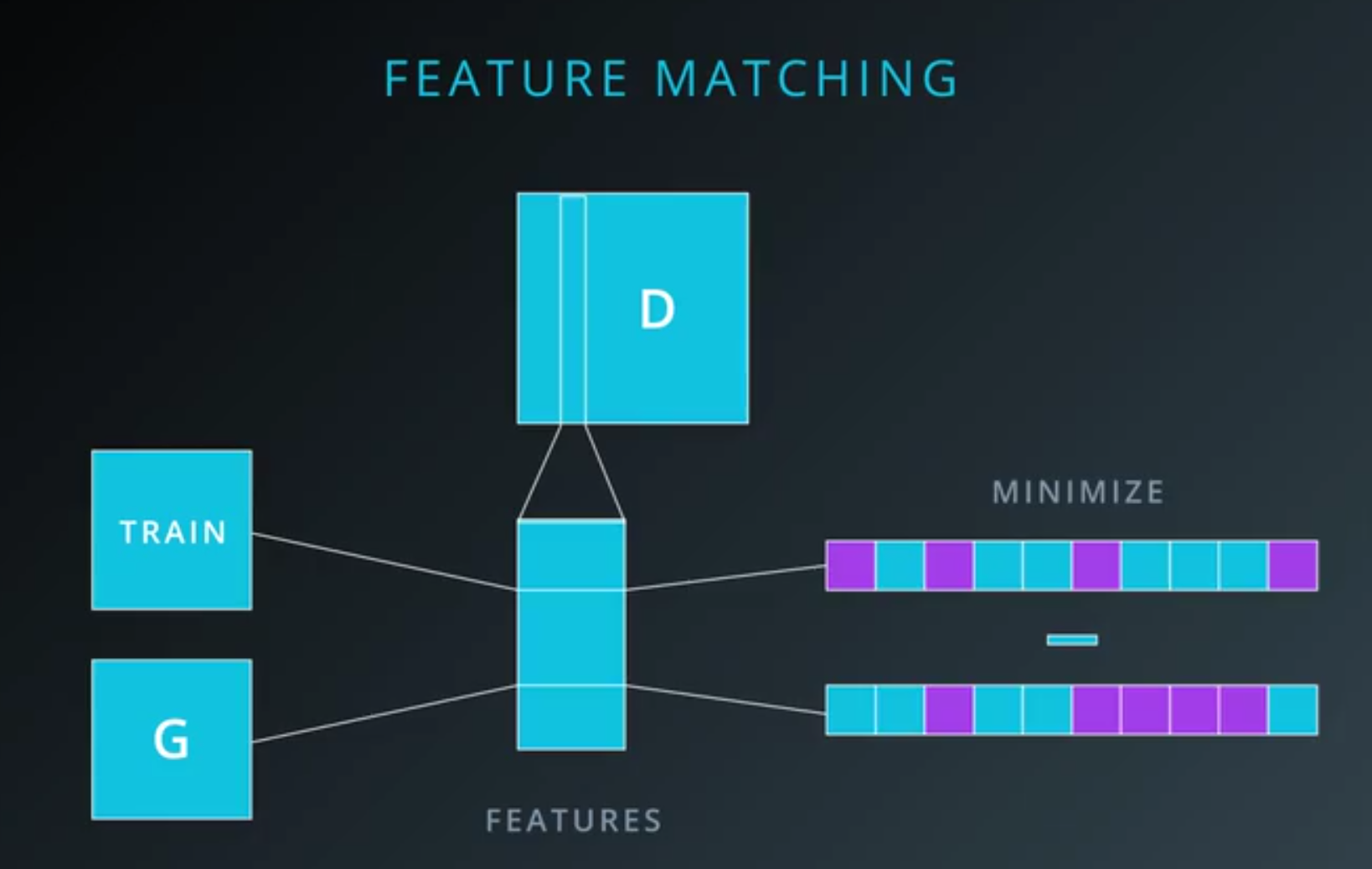
- The idea of feature matching is
- to add a term to the cost function for the generator,
- penalizing the mean absolute error between
- the average value of some set of features on the training data,
- and the average value of that set of features on the generated samples.
- The set of features can be any group of hidden units from the discriminator.
- The idea of feature matching is
- Now we can train the model using the sum of two costs.
- So semi-supervised learning still as some catching up
- to do compared to the brute force approach of just gathering tons and tons of labeled data.
- Usually, labeled data is the bottleneck
- that determines which tasks we are or aren’t able to solve with machine learning.
- Hopefully using semi-supervised GANs,
- you’ll be able to tackle a lot of problems that weren’t possible before.